自然语言转换成SQL查询
NL2SQL
NL2SQL任务
NL2SQL(Natural Language to SQL), 顾名思义,是一项将自然语言转为可执行 SQL 语句的技术。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,对改善用户与数据库之间的交互方式有很大意义。
NL2SQL 的价值
当前,大量信息存储在结构化和半结构化知识库中,如数据库。对于这类数据的分析和获取需要通过SQL等编程语言与数据库进行交互操作,SQL的使用难度限制了非技术用户,给数据分析和使用带来了较高的门槛。人们迫切需要技术或工具完成自然语言与数据库的交互,因此诞生了Text-to-SQL任务。NL2SQL图示如下:
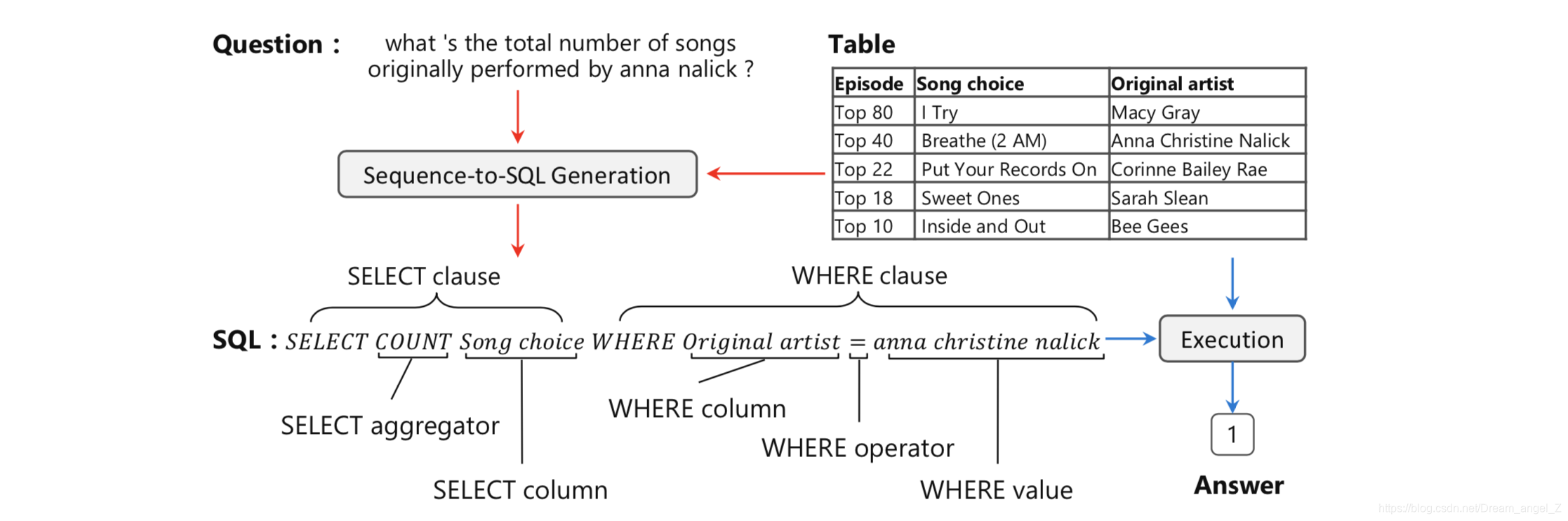
我们通过图1中的实例来介绍一下Text-to-SQL任务。该任务包含两部分:Text-to-SQL解析器和SQL执行器。
解析器的输入是给定的数据库和针对该数据库的问题,输出是问题对应的SQL查询语句,如图中红色箭头标示。SQL执行器在数据库上完成该查询语句的执行,及给出问题的最终答案,如图中绿色箭头标示。
SQL执行器有很多成熟的系统,如MySQL,SQLite等,该部分不是本文重点。本文主要介绍解析器,学术界中Text-to-SQL任务默认为Text-to-SQL解析模型。

根据SQL的构成,解析器需要完成两个任务,即“问题与数据库的映射”和“SQL生成”。
在问题与数据库的映射中,需要找出问题依赖的表格以及具体的列,如图1实例中,问题“绿化率前5的城市有哪些,分别隶属于哪些省?”依赖的数据库内容包括:表格“中国城市”,具体的列“名称”、“所属省”、“绿化率”(SQL查询语句蓝色标注成分)。
在SQL生成中,结合第一步识别结果以及问题包含信息,生成满足语法的SQL查询语句,如实例中的“Select 名称,所属省 From 中国城市 Where 绿化率 > 30%”。
Text-to-SQL研究进展
我们接下来将从相关数据集和模型两方面介绍该技术的研究进展。
1、数据集介绍
图2给出了Text-to-SQL数据集发展趋势,代表数据集参见表1。
目前,NL2SQL 方向已经有 WikiSQL、Spider、WikiTableQuestions、ATIS 等诸多公开数据集,如图所示:
不同数据集都有各自的特点,这里简单介绍一下这四个数据集:
- WikiSQL:该数据集是Salesforce在2017年提出的大型标注NL2SQL数据集,也是目前规模最大的NL2SQL数据集。它包含了 24,241张表,80,645条自然语言问句及相应的SQL语句。目前学术界的预测准确率可达91.8%。
- Spider:Spider数据集是耶鲁大学于2018年新提出的一个较大规模的NL2SQL数据集。该数据集包含了10,181条自然语言问句,分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。虽然在数据数量上不如WikiSQL,但Spider引入了更多的SQL用法,例如Group By、Order By、Having等高阶操作,甚至需要Join不同表,更贴近真实场景,所以难度也更大。目前准确率最高只有54.7%
- WikiTableQuestions 是斯坦福大学于 2015 年提出的一个针对维基百科中那些半结构化表格问答的数据集,包含了 22,033 条真实问句以及 2,108 张表格。
- The Air Travel Information System (ATIS) 是一个年代较为久远的经典数据集,由德克萨斯仪器公司在 1990 年提出。该数据集获取自关系型数据库 Official Airline Guide (OAG, 1990),包含 27 张表以及不到 2,000 次的问询,每次问询平均 7 轮,93% 的情况下需要联合 3 张以上的表才能得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信息。
- 中文数据集目前只有追一科技在天池发布的比赛数据集,包括4万条有标签数据作为训练集,1万条无标签数据作为测试集。目前比赛第一名的成绩,准确率达到了92%。
2、模型介绍
SQL查询语句是一个符合语法、有逻辑结构的序列,其构成来自三部分:数据库、问题、SQL关键词。
在当前深度学习研究背景下,Text-to-SQL任务可被看作是一个类似于神经机器翻译的序列到序列的生成任务,主要采用Seq2Seq模型框架。基线Seq2Seq模型加入注意力、拷贝等机制后,在单领域数据集上可以达到80%以上的准确率,但在多领域数据集上效果很差,准确率均低于25%。
从编码和解码两个方面进行原因分析:
在编码阶段,问题与数据库之间需要形成很好的对齐或映射关系,即问题中涉及了哪些表格中的哪些元素(包含列名和表格元素值);同时,问题与SQL语法也需要进行映射,即问题中词语触发了哪些关键词操作(如Group、Order、Select、Where等)、聚合操作(如Min、Max、Count等)等;最后,问题表达的逻辑结构需要表示并反馈到生成的SQL查询语句上,逻辑结构包括嵌套、多子句等。
在解码阶段,SQL语言是一种有逻辑结构的语言,需要保证其语法合理性和可执行性。普通的Seq2Seq框架并不具备建模这些信息的能力。
当前基于Seq2Seq框架,主要有以下几种改进:
1)基于Pointer Network的改进
首先,SQL组成来自三部分:数据库中元素(如表名、列名、表格元素值)、问题中词汇、 SQL关键字。其次,当前公开的多领域数据集为了验证模型数据库无关,在划分训练集和测试集时要求数据库无交叉,这种划分方式导致测试集数据库中很大比例的元素属于未登录词。传统的Seq2Seq模型是解决不好这类问题的。
Pointer Network很好地解决了这一问题,其输出所用到的词表是随输入而变化的。具体做法是利用注意力机制,直接从输入序列中选取单词作为输出。在Text-to-SQL任务中,将问题中词汇、SQL关键词、对应数据库的所有元素作为输入序列,利用Pointer Network从输入序列中拷贝单词作为最终生成SQL的组成元素。
由于Pointer Network可以较好的满足具体数据库无关这一要求,在多领域数据集上的模型大多使用该网络,如Seq2SQL[1]、STAMP[8]、Coarse2Fine[9] 、IRNet[16]等模型。
2)基于Sequence-to-set的改进
在简单问题对应的数据集合上,其SQL查询语句形式简单(仅包含Select和Where关键词),为了解决Seq2Seq模型中顺序错误带来的影响(如“条件1 And 条件2”,预测为“条件2 And 条件1”,属于顺序错误,但对应的SQL是正确的),SQLNet[10]提出了Sequence-to-set模型,基于所有的列预测其属于哪个关键词(即属于Select还是Where,在SQLNet模型中仅预测是否属于Where),针对SQL 中每一个关键词选择概率最高的前K个列。
该模式适用于SQL形式简单的数据集,在WikiSQL和NL2SQL这两个数据集合上使用较多,且衍生出很多相关模型,如TypeSQL[11]、SQLova[12]、X-SQL[13]等。
3、评价方法
Text-to-SQL任务的评价方法主要包含两种:精确匹配率(Exact Match, Accqm)、执行正确率(Execution Accuracy, Accex)。
精确匹配率指,预测得到的SQL语句与标准SQL语句精确匹配成功的问题占比。为了处理由成分顺序带来的匹配错误,当前精确匹配评估将预测的SQL语句和标准SQL语句按着SQL关键词分成多个子句,每个子句中的成分表示为集合,当两个子句对应的集合相同则两个子句相同,当两个SQL所有子句相同则两个SQL精确匹配成功;
执行正确指,执行预测的SQL语句,数据库返回正确答案的问题占比。
目前仅WikiSQL数据集支持Accex,其他数据集仅支持Accqm。大部分数据集发布了对应的评估脚本,方便大家在同一个评估标准下进行算法研究。
4、NL2SQL实现简述
NL2SQL的基本思路是打造一条从自然语言到SQL的转换链路,多采用的是语义解析和规则的方式构建NL2SQL系统,其架构大体如下:

- 用户UI:用户交互界面,包括问句自动提示、可视化选择等功能。
- Storage:Storage是数据存储中心,包括了Knowledge Graph、Intent words以及database schema信息。同时也会将用户的搜索log存储起来。
- Parser:主要负责对user query进行parsing,包括了annotator(字符串匹配+NER+意图识别等一系列操作)、grammar(语法检测)、semantic predict(语义预测)、ranking(评分排序)。这部分会调用借助图谱来提高实体和关系识别精度。
- Answering Engine:用于将语义解析的结果转换成SQL,包括表识别、查询语句生成器等,最终将结果(数据、可视化结果、SQL等)返回给user。
XSQL
- 论文地址: https://arxiv.org/pdf/1908.08113
- X-SQL 的 Query Structure

- X-SQL是微软提出的NL2SQL模型,参考了SQLNet、SQLova等模型的思路.
- X-SQL 的模型架构分为三层 (如下所示):
- Encoder: 首先使用 bert 风格的预训练模型(MT-DNN) 对 Question 和 SQL 表格进行编码和特征提取, 得到上下文输出来增强结构模式表示,并结合类型信息;
- Context Reinforcing Layer: 该结构用于增强在 equence Encoder (序列编码器)得到的 H_[CTX], 从而得到增强的语义表示 HCi ;
- Output Layer: 输出层完成 SQL 语句的生成,我们将其分为 6 个子任务(select-column, select-aggregation, where-number, where-column, where-operator, and where-value),这六个任务彼此之间相互结合,彼此制约。

X-SQL模型—Encoder
X-SQL使用了一个BERT-Like模型MT-DNN作为Token Sequence Encoder,同时进行以下修改:
- 引入了一个特殊空列
[EMPTY]的概念,并将其追加到每个Table Schema后面; - BERT中的
Segment Embedding被替换为Type Embedding,包括:Question 、Categorial Column、Numerical Column、Special Empty Column 这四种类型; - 此外,单纯地将标志位
[CLS]重命名为[CTX]

X-SQL模型—Context Reinforcing Layer
- 对上一层Encoder的输出 H_[CTX] 进一步“强化”,从而为表的每一列学习新的表示h_Ci
- 这种强化体现在两方面:
- 由于Column Tokens的输出长短不一,所以需要对Column Embeddings进行“调整”;
- 此外为了加强Context的影响,在Alignment Model中会使用到Context Embedding的信息;

通过这种方式可以捕获到哪一个查询词与哪一列最相关,从而得到增强的语义表示 HCi 。它的计算过程如下所示:
其中,$f$只是普通的点乘 (dot-product) 操作。最后,针对每一列 (schema representation h_Ci),独立的使用下面的子网络结构得到使用融合 h_Ci 和 hctx 的 rCi,公式如下所示:
X-SQL模型—Output Layer
Output层由六个子分类器构成:
- S-COL:查询表的哪一列
- S-AGG: 使用什么聚合函数
- W-NUM: 查找where子句的数量(四个可能标签的分类,每个标签表示1~4 )
- W-COL:选择表的哪几列
- W-OP: 对这几列的操作符
- W-VAL: 这几列的值
其中五个子模型的输出会被填到QueryStructure中。w-col、w-op 和 w-val 这三个任务是依赖 w-num 的,因为 w-num 决定了对几列进行约束,这样它们三个只需要取 softmax 最大的那几个。

每个子模型的说明:

在训练过程中,我们优化目标是所有单个子任务损失的总和。
任务描述
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
模型的输入为一个 Question + Table,输出一个 SQL 结构,该 SQL 结构对应一条 SQL 语句。示例如下图黄色部分,需要预测的有4部分:
- 挑选的列(sel)
- 列上的聚合函数(agg)
- 筛选的条件(conds)
- 条件间的关系(cond_conn_op)

任务数据
4万条有标签数据作为训练集
1万条无标签数据作为测试集
评价指标
- 全匹配率 (Logic Form Accuracy): 预测完全正确的SQL语句。其中,列的顺序并不影响准确率的计算。
- 执行匹配率 (Execution Accuracy): 预测的SQL的执行结果与真实SQL的执行结果一致。
官方的评估指标是 (全匹配率 + 执行匹配率) / 2,也就是说你有可能写出跟标注答案不同的SQL语句,但执行结果是一致的,这也算正确一半。
难点分析
- 不限制使用表格内容信息
- 存在conds value不能从question提取的样本
- select agg存在多项
- 没有conds缺失的样本
第一名解决方案M-SQL
- 将原始的 Label 做一个简单的变换

- 对输入进行改造
将 Question 与 Header 顺序连接, 其中每一个表头也视为一个句子,用[CLS]***[SEP]括住。
- M-SQL 模型架构
第一个[CLS]对应的向量,我们可以认为是整个问题的句向量,我们用它来预测XXX的连接符。后面的每个[CLS]对应的向量,我们认为是每个表头的编码向量,我们把它拿出来,用来预测该表头表示的列是否应该被select . 现在就剩下比较复杂的conds了,就是where col_1 == value_1这样子的,col_1、value_1以及运算符==都要找出来。
两个较特殊的改进:
- W-col-val模型
- 相较于X-SQL的W-VAL预测Value的首尾偏移量,W-col-val改用了序列标注的方式提取Where Value;
- W-val-match模型
- 提取各列的 Distinct Value Set,基于Matching的方式匹配最可能的【列-值】;
- 基于文本的匹配:rouge-L、编辑距离等;
- 基于语义的匹配:LR、MLP、相似度计算等
- 提取各列的 Distinct Value Set,基于Matching的方式匹配最可能的【列-值】;

M-SQL在X-SQL的基础上进行了调整和扩展(对比)
- Encoder:
- 预训练模型更换(MT-DNN → Bert-wwm-ext);
- Token/TokenType调整;
- Column Representation:基本和X-SQL一致;
- Sub-models:
- 增加S-num辅助任务
- 合并W-NUM和Reducer预测;
- 将原本的W-VAL换成了W-col-val和W-val-match;
- (待定) 把sel与agg结合,当作多分类问题

现阶段的问题
- WikiSQL 数据集的数据形式和功能薄弱
- 条件的表达只支持最基础的
>、<、= - 条件之间的关系只有
and - 不支持聚组、排序、嵌套等其它众多常用的 SQL 语法
- 不需要联合多表查询答案,真实答案所在表格已知
- 这样的数据集并不符合真实的应用场景
- 条件的表达只支持最基础的
- Query Structure中的元素不存在递归关系
- 天池TableQA(5w,中文),样本量少,且结构简单
如何更好地结合数据库信息来理解并表达用户语句的语义、如何编码及表达数据库的信息、如何生成复杂却有必要的 SQL 语句,此类挑战还有很多需要解决,它们都是非常值得探索的方向。
补充
现在Bert可用的中文预训练权重有两个
两个的最终效果差不多,但是哈工大版的收敛更快。
复现过程
Part1: 预处理
首先对question进行了格式统一,具体如下:
- 百分数转换,例如百分之10转化为10%,百分之十转换为10%, 百分之一点五转化为1.5%
- 大写数字转阿拉伯数字,例如十二转换为12; 二十万转化为200000; 一点二转化为1.2
- 年份转换,如将12年转换为2012年
- 利用规则与编辑距离对query进行修正
- query信息标记:[CLS] -> [XLS]
然后,SQL分析
- 常用的SQL模式分析
Part2:模型介绍
- 预训练模型:Bert-wwm-ext,哈工大
- W-num,W-op融合
Part3: 后处理
Part4: 模型效果评估
Part5: 网络/应用
通过云服务构建服务器后,构建可与各种DBMS链接的网页
参考
RAdam 优化器的实现 keras_radam
CyberZHG 大神的开源项目 keras-bert
哈工大讯飞联合实验室的 Chinese-BERT-wwm 项目
自然语言到 SQL 语句,微软只用六个子任务,结果超越人类水平
X-SQL,X-SQL: REINFORCE CONTEXT INTO SCHEMA REPRESENTATION
M-SQL,M-SQL:Muti-Schema Representation Learning for Single-Table Text2SQL Generation(修改中…)