字符串模糊匹配指南
字符串模糊匹配指南
- textdistance: 30+传统的字面距离计算 √
- difflib: Python自带的计算文本差异的辅助工具 √
- fuzzywuzzy: 依据编辑算法计算两个序列之间的差异
- strsimpy: 计算各种字符串距离的包
- Fast Fuzzy Matching: 快
textdistance库 ❤❤❤
textdistance 库使用传统的字面匹配算法来综合评估两段文本的匹配程度!它使用30多种不同的算法计算序列的距离,提供了可用于模糊匹配算法的集合.
1 | |
All algorithms have some common methods:
.distance(*sequences)— calculate distance between sequences..similarity(*sequences)— calculate similarity for sequences..maximum(*sequences)— maximum possible value for distance and similarity. For any sequence:distance + similarity == maximum..normalized_distance(*sequences)— normalized distance between sequences. The return value is a float between 0 and 1, where 0 means equal, and 1 totally different..normalized_similarity(*sequences)— normalized similarity for sequences. The return value is a float between 0 and 1, where 0 means totally different, and 1 equal.
Levenshtein距离
指两个字串之间,由一个转成另一个所需的最少编辑操作次数。
1 | |
Jaccard 相似度
1 | |
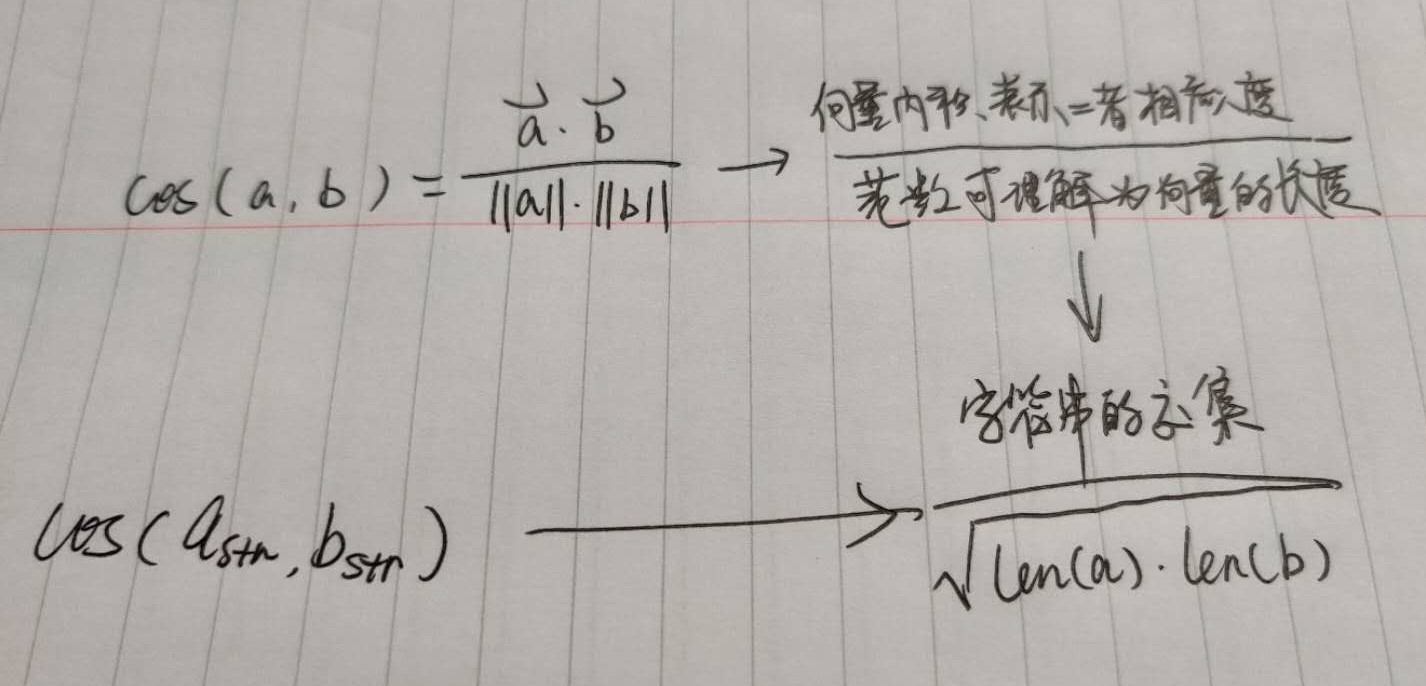
余弦相似度
余弦相似度是比较两个字符串的常用方法。该算法将字符串视为向量,并计算它们之间的余弦值。与上面的 Jaccard Similarity 相似,余弦相似度也忽略了要比较的字符串中的顺序。
1 | |
difflib库 ❤❤❤
difflib —- 计算差异的辅助工具
此模块提供用于比较序列的类和函数,有以下内容:
_class_ **difflib.SequenceMatcher**
这是一个灵活的类,可用于比较任何类型的序列对,只要序列元素为 hashable 对象。 其思路是找到不包含“垃圾”元素的最长连续匹配子序列;所谓“垃圾”元素是指其在某种意义上没有价值,例如空白行或空白符。然后同样的思路将递归地应用于匹配序列的左右序列片段。 这并不能产生最小编辑序列,但确实能产生在人们看来“正确”的匹配。
自动垃圾启发式计算: [SequenceMatcher](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.SequenceMatcher) 支持使用启发式计算来自动将特定序列项视为垃圾。 这种启发式计算会统计每个单独项在序列中出现的次数。 如果某一项(在第一项之后)的重复次数超过序列长度的 1% 并且序列长度至少有 200 项,该项会被标记为“热门”并被视为序列匹配中的垃圾。 这种启发式计算可以通过在创建 [SequenceMatcher](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.SequenceMatcher) 时将 autojunk 参数设为 False 来关闭。
_class_ **difflib.Differ**
这个类的作用是比较由文本行组成的序列,并产生可供人阅读的差异或增量信息。 Differ 统一使用 [SequenceMatcher](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.SequenceMatcher) 来完成行序列的比较以及相似(接近匹配)行内部字符序列的比较。
[Differ](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.Differ) 增量的每一行均以双字母代码打头:
| 双字母代码 | 含义 |
|---|---|
'- ' |
行为序列 1 所独有 |
'+ ' |
行为序列 2 所独有 |
' ' |
行在两序列中相同 |
'? ' |
行不存在于任一输入序列 |
**difflib.get_close_matches**(_word_, _possibilities_, _n=3_, _cutoff=0.6_)
返回由最佳“近似”匹配构成的列表。
_word_ 为一个指定目标近似匹配的序列(通常为字符串),_possibilities_ 为一个由用于匹配 _word_ 的序列构成的列表(通常为字符串列表)。可选参数 _n_ (默认为 3) 指定最多返回多少个近似匹配; _n_ 必须大于 0;可选参数 _cutoff_ (默认为 0.6) 是一个 [0, 1] 范围内的浮点数。 与 _word_ 相似度得分未达到该值的候选匹配将被忽略。候选匹配中(不超过 _n_ 个)的最佳匹配将以列表形式返回,按相似度得分排序,最相似的排在最前面。
1 | |
**difflib.ndiff**(_a_, _b_, _linejunk=None_, _charjunk=IS_CHARACTER_JUNK_)
比较 _a_ 和 _b_ (字符串列表);返回 [Differ](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.Differ) 形式的增量信息 (一个产生增量行的 generator)。
可选关键字形参 _linejunk_ 和 _charjunk_ 均为过滤函数 (或为 None)
SequenceMatcher 对象
[SequenceMatcher](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.SequenceMatcher) 类具有这样的构造器:
- _class_
difflib.SequenceMatcher(_isjunk=None_, _a=’’_, _b=’’_, _autojunk=True_)
可选参数isjunk必须是none(默认值)等同于传递lambda x:0;换句话说,不忽略任何元素;可选参数 _autojunk_ 可用于启用自动垃圾启发式计算。
[SequenceMatcher](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.SequenceMatcher) 对象具有以下方法:
find_longest_match(_alo_, _ahi_, _blo_, _bhi_) √
源码解析。找出 a[alo:ahi] 和 b[blo:bhi] 中的最长匹配块。如果 _isjunk_ 被省略或为 None,[find_longest_match()](https://docs.python.org/zh-cn/3.7/library/difflib.html#difflib.SequenceMatcher.find_longest_match) 将返回 (i, j, k) 使得 a[i:i+k] 等于 b[j:j+k]
1 | |
get_matching_blocks()
返回描述非重叠匹配子序列的三元组列表。 每个三元组的形式为 (i, j, n),其含义为 a[i:i+n] == b[j:j+n]。 这些三元组按 _i_ 和 _j_ 单调递增排列。
最后一个三元组用于占位,其值为 (len(a), len(b), 0)。 它是唯一 n == 0 的三元组。 如果 (i, j, n) 和 (i', j', n') 是在列表中相邻的三元组,且后者不是列表中的最后一个三元组,则 i+n < i' 或 j+n < j';换句话说,相邻的三元组总是描述非相邻的相等块。
1 | |
get_opcodes() √
返回描述如何将 _a_ 变为 _b_ 的 5 元组列表,每个元组的形式为 (tag, i1, i2, j1, j2)。 在第一个元组中 i1 == j1 == 0,而在其余的元组中 _i1_ 等于前一个元组的 _i2_,并且 _j1_ 也等于前一个元组的 _j2_。
_tag_ 值为字符串,其含义如下:
| 值 | 含义 |
|---|---|
'replace' |
a[i1:i2] 应由 b[j1:j2] 替换。 |
'delete' |
a[i1:i2] 应被删除。 请注意在此情况下 j1 == j2。 |
'insert' |
b[j1:j2] 应插入到 a[i1:i1]。 请注意在此情况下 i1 == i2。 |
'equal' |
a[i1:i2] == b[j1:j2] (两个子序列相同)。 |
代码如下:
1 | |
ratio()
返回一个取值范围 [0, 1] 的浮点数作为序列相似性度量。
其中 T 是两个序列中元素的总数量,M 是匹配的数量,即 2.0*M / T。 请注意如果两个序列完全相同则该值为 1.0,如果两者完全不同则为 0.0。
如果 get_matching_blocks() 或 get_opcodes() 尚未被调用则此方法运算消耗较大,在此情况下你可能需要先调用 quick_ratio() 或 real_quick_ratio() 来获取一个上界。
1 | |
Differ 对象
这个类的作用是比较由文本行组成的序列,并产生可供人阅读的差异或增量信息。 Differ 统一使用 SequenceMatcher 来完成行序列的比较以及相似(接近匹配)行内部字符序列的比较。
Differ 类具有这样的构造器:
_class_
difflib.``Differ(_linejunk=None_, _charjunk=None_)可选关键字形参 _linejunk_ 和 _charjunk_ 均为过滤函数 (或为
None):
Differ 对象是通过一个单独方法来使用(生成增量)的:
compare(a, b)
比较两个由行组成的序列,并生成增量(一个由行组成的序列)。
每个序列必须包含一个以换行符结尾的单行字符串。 这样的序列可以通过文件类对象的 readlines() 方法来获取。 所生成的增量同样由以换行符结尾的字符串构成,可以通过文件类对象的 writelines() 方法原样打印出来。
fuzzywuzzy
FuzzyWuzzy 是一个简单易用的模糊字符串匹配工具包。它依据 Levenshtein Distance 算法 计算两个序列之间的差异。
导入库
1 | |
简单匹配
1 | |
非完全匹配
1 | |
忽略顺序匹配
1 | |
去重子集匹配
1 | |
Process返回模糊匹配的字符串和相似度
1 | |
可以传入附加参数到 extractOne 方法来设置使用特定的匹配模式,一个典型的用法是来匹配文件路径
1 | |
strsimpy
这是一个用于计算各种字符串距离的包。其使用方法如下:
1 | |
Fast Fuzzy Matching
通过 ngram 寻找紧密匹配的对象。这种查找紧密匹配的方法不仅应该非常有效,而且还可以通过其对整个数据中不太常见的字符组更加重视的能力来产生高质量的匹配项。
使用字符串相似性度量,例如Jaro-Winkler或Levenshtein距离度量,存在着一个明显的问题,就是所需的计算量呈二次方增长(必须将每个条目与数据集中的每个其他条目进行比较)。该方法最大的优势是速度,使用 TF-IDF、N-Grams 和稀疏矩阵乘法更快地完成模糊匹配!
示例代码:
https://bergvca.github.io/2017/10/14/super-fast-string-matching.html