摘要
《MIXED PRECISION TRAINING》这篇论文是百度&Nvidia研究院一起发表的,结合N卡底层计算优化,提出了一种灰常有效的神经网络训练加速方法,不仅是预训练,在全民finetune BERT的今天变得异常有用哇。而且小夕调研了一下,发现不仅百度的paddle框架支持混合精度训练,在Tensorflow和Pytorch中也有相应的实现。下面我们先来讲讲理论,后面再分析混合精度训练在三大深度学习框架中的打开方式。
另外,推荐一个省显存的优化器文章《硬核推导Google AdaFactor:一个省显存的宝藏优化器》 以及节省显存的重计算技巧也有了Keras版了
理论原理
训练过神经网络的小伙伴都知道,神经网络的参数和中间结果绝大部分都是单精度浮点数(即float32)存储和计算的,当网络变得超级大时,降低浮点数精度,比如使用半精度浮点数,显然是提高计算速度,降低存储开销的一个很直接的办法。然而副作用也很显然,如果我们直接降低浮点数的精度直观上必然导致模型训练精度的损失。但是呢,天外有天,这篇文章用了三种机制有效地防止了模型的精度损失。
- 权重备份(master weights)
- 损失放缩(loss scaling)
- 运算精度(precison of ops)
总结陈词混合精度训练做到了在前向和后向计算过程中均使用半精度浮点数,并且没有像之前的一些工作一样还引入额外超参,而且重要的是,实现非常简单却能带来非常显著的收益,在显存half以及速度double的情况下保持模型的精度,简直不能再厉害啦。
混合精度训练[5]不是很难理解,但要注意以下几点:
- 混合精度训练不是单纯地把FP32转成FP16去计算就可以了,只用FP16会造成80%的精度损失
- Loss scaling:由于梯度值都很小,用FP16会下溢,因此先用FP32存储loss并放大,使得梯度也得到放大,可以用FP16存储,更新时变成FP32再缩放
- 在涉及到累加操作时,比如BatchNorm、Softmax,FP16会上溢,需要用FP32保存,一般使用GPU中TensorCore的FP16*FP16+FP32=FP32运算
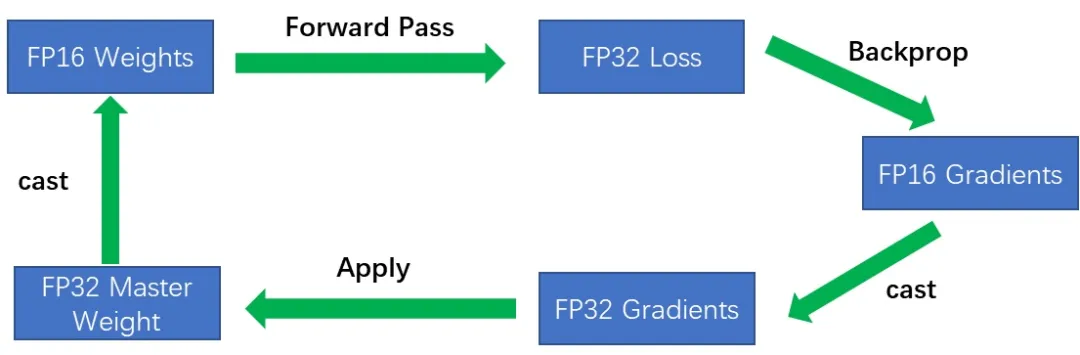
整体流程:FP32权重 -> FP16权重 -> FP16计算前向 -> FP32的loss,扩大 -> 转为FP16 -> FP16反向计算梯度 -> 缩放为FP32的梯度更新权重
三大深度学习框架的打开方式
Pytorch
导入Automatic Mixed Precision (AMP),不要998不要288,只需3行无痛使用!
1
2
3
4
| from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
|
来看个例子,将上面三行按照正确的位置插入到自己原来的代码中就可以实现酷炫的半精度训练啦!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import torch
from apex import amp
model = ...
optimizer = ...
#包装model和optimizer
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
for data, label in data_iter:
out = model(data)
loss = criterion(out, label)
optimizer.zero_grad()
#loss scaling,代替loss.backward()
with amp.scaled_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
|
Tensorflow
一句话实现混合精度训练之修改环境变量,在python脚本中设置环境变量
1
| os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
|
另外还需要对优化器(Optimizer)作如下修改:
1
2
3
4
| opt = tf.train.AdamOptimizer(learning_rate=learning_rate)
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(
opt,
loss_scale='dynamic') # 需要添加这句话,该例子是tf1.14.0版本,不同版本可能不一样
|
Keras-based示例
1
2
3
4
5
6
7
| opt = tf.keras.optimizers.Adam()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(
opt,
loss_scale='dynamic')
model.compile(loss=loss, optimizer=opt)
model.fit(...)
|
PaddlePaddle
一句话实现混合精度训练之添加config(惊呆?毕竟混合精度训练是百度家提出的,内部早就熟练应用了叭)
举个栗子,基于BERT finetune XNLI任务时,只需在执行时设置use_fp16为true即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| export FLAGS_sync_nccl_allreduce=0
export FLAGS_eager_delete_tensor_gb=1
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
BERT_BASE_PATH="chinese_L-12_H-768_A-12"
TASK_NAME='XNLI'
DATA_PATH=/path/to/xnli/data/
CKPT_PATH=/path/to/save/checkpoints/
python -u run_classifier.py --task_name ${TASK_NAME} \
--use_fp16=true \ #!!!!!!add a line
--use_cuda true \
--do_train true \
--do_val true \
--do_test true \
--batch_size 32 \
--in_tokens false \
--init_pretraining_params ${BERT_BASE_PATH}/params \
--data_dir ${DATA_PATH} \
--vocab_path ${BERT_BASE_PATH}/vocab.txt \
--checkpoints ${CKPT_PATH} \
--save_steps 1000 \
--weight_decay 0.01 \
--warmup_proportion 0.1 \
--validation_steps 100 \
--epoch 3 \
--max_seq_len 128 \
--bert_config_path ${BERT_BASE_PATH}/bert_config.json \
--learning_rate 5e-5 \
--skip_steps 10 \
--num_iteration_per_drop_scope 10 \
--verbose true
|
参考
【DL】模型训练太慢?显存不够用?这个算法让你的GPU老树开新花
用于深度学习的自动混合精度
