深度学习困难样本采样(Hard Mining)
深度学习困难样本采样(Hard Mining)
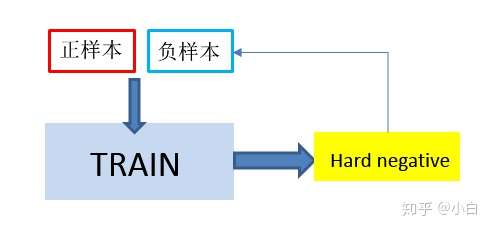
定义
hard negative mining顾名思义:negative,即负样本,其次是hard,说明是困难样本,也就是说在对负样本分类时候,loss比较大(label与prediction相差较大)的那些样本,也可以说是容易将负样本看成正样本的那些样本。
要他有何用?
数据决定了上限,模型只是拟合上限
问题挑战:分布不一致问题。经典统计机器学习的基础假设是训练集和测试集分布一致,不一致的分布通常会导致模型学偏,训练集和验证集效果难以对齐。最直观的不一致是,大多训练集中只有正样本,没有负样本。
因此,为嵌入模型设计一个训练数据集,以便在该空间上高效有效地学习非常重要。
为了解决这个问题,hard mining是一个主要的方向,我们需要设计负采样策略来构造负样本,并尽可能使得采样出的负样本靠近测试集真实分布。
采样策略
KDD Cup 2020 多模态召回比赛季军方案与广告业务应用
在大多情况下,候选之间通常有着紧密的语义关联,需要在较细的属性粒度上对文本进行匹配的。适当增加训练数据中的强负例的难度,有助于提升模型效果。一般的做法是,从一个排序的候选段落中进行采样,越靠前的负例对模型来说难度越大。但是由于难以避免的漏标注情况,直接采样很大概率会引入假负例。
我们设计了如下表所示的四种采样策略来构建样本集。这四种策略中,随机采样得到的正负样本最容易被区分,难以区分相似的结果,需要更接近正样本的样本作为训练中的hard negative;在训练中,我们从基准模型出发,先在最简单的随机采样上训练基准模型,然后在更困难的按question标签采样、按 Query 的聚类采样的样本集上基于先前的模型继续训练,最后combination采样的样本集上训练。这样由易到难、由远到近的训练方式,有助于模型收敛到验证集分布上,在测试集上取得了更好的效果。
| 采样策略 | 描述 | 与验证集贴近程度 |
|---|---|---|
| 随机采样 | 知识库中存在大量标准问和相似问的匹配对,将这些匹配对当作正样本; 随机抽取一条与标准问不匹配的标准问作为负样本,正负样本比例为 1:1 |
弱 |
| 1、按question类别采样 | 将全部question按照其类别聚类; 对每个Query,在其对应的question所属的category_id中, 进行随机采样,作为负样本(same topic);原始样本为正样本 |
中 |
| 2、按Query的聚类采样 | 将全部Query按照Word Embedding进行聚类; 对每个question,在其对应的Query所属的聚类中, 进行随机采样,作为负样本;原始样本为正样本 |
较强 |
| combination | 50%负样本随机采样自同一类别,其余50%随机采样自其他类别; | 较强 |
简单地使用hard negative来训练的模型不能比使用random negative来训练的模型表现更好。我们发现使用hardest例子并不是最好的策略。我们比较了不同排名位置的抽样,发现在排名101-500之间抽样的模型获得最好的recall。此外,在训练数据中存在easy negatives仍然是必要的,因为检索模型是在一个输入空间上操作的,该空间包含具有各种hard级别的数据,其中大多数是easy negatives。因此,在训练中混合random和hard的negative是有用的。增加easy negatives对hard negatives的比率将继续提高模型的召回, 在easy:hard=100:1的比例时趋于饱和结果。
Trick:
focal loss解决hard sample mining。如果不知道怎么找准对应场景的困难样本,同时暂时也还在用交叉熵做二分类loss的话,可以无脑迁移focal loss。