降维方法总结
在现实生活中很多机器学习问题有上千维,甚至上万维特征,这不仅影响了训练速度,通常还很难找到比较好的解。这样的问题成为维数灾难(curse of dimensionality)
幸运的是,理论上降低维度是可行的。比如MNIST数据集大部分的像素总是白的,因此可以去掉这些特征;相邻的像素之间是高度相关的,如果变为一个像素,相差也并不大。
需要注意:降低维度肯定会损失一些信息,这可能会让表现稍微变差。因此应该先在原维度训练一次,如果训练速度太慢再选择降维。虽然有时候降为能去除噪声和一些不必要的细节,但通常不会,主要是能加快训练速度。
降维除了能提高训练速度以外,还能用于数据可视化。把高维数据降到2维或3维,然后就能把特征在2维空间(3维空间)表示出来,能直观地发现一些规则。
1.降维的主要方法
降维的方法主要为两种:projection 和 Manifold Learning。
1.1 投影(Projection)
在大多数的真实问题,训练样例都不是均匀分散在所有的维度,许多特征都是固定的,同时还有一些特征是强相关的。因此所有的训练样例实际上可以投影在高维空间中的低维子空间中,下面看一个例子。

可以看到3维空间中的训练样例其实都分布在同一个2维平面,因此我们能够将所有样例都投影在2维平面。对于更高维的空间可能能投影到低维的子空间中。
然而投影(projection)不总是降维最好的方法在,比如许多情况下,空间可以扭转,如著名的瑞士卷(Swiss roll)数据。

如果简单的使用投影(project)降维(例如通过压平第3维),那么会变成如下左图的样子,不同类别的样例都混在了一起,而我们的预想是变成右下图的形式。

1.2 流形学习(Manifold Learning)
从降维的角度来看,流形学习是除了核方法之外实现非线性降维的另一类重要手段。流形学习的一个基本假设是样本分布在一个潜在的流形之上,所以尽管输入空间的维数很高,但流形的内在维度一般不是很高。如图4所示,左图是三维空间中的一个S曲面流形,其内在维度是二维。中间图是对流形进行采样而来,右图是经流形学习算法局部线性嵌入把流形展在二维平面所得到的结果。
在等度规映射和局部线性嵌入之后,出现了一系列流形学习算法,主要包括拉普拉斯特征映射(Laplacian Eigenmaps,LE)、最大方差延展(Maximum Variance Unfolding,MVU)和局部正切空间对齐(Local TangentSpace Alignment, LTSA)等。相比传统线性降维算法,流形学习尽管能有效处理非线性问题,但多数流形算法存在计算效率低下、不能推广到Out-of-sample等问题。后续算法针对上述问题分别做出了许多改进,其中有代表性的是何(X.He)等人所提出的局部保持投影(Local Preserving Projection,LPP)。它实际上是拉普拉斯特征映射的线性化版本。在局部保持投影之外,出现了很多局部化的降维算法,这些方法中都利用了局部保持的思想,即在高维空间中相邻的样本在投影后的低维空间中也应该相邻,一般是通过k近邻(K-NearestNeighbor,k-NN)或ε邻域来度量近邻关系并用一个图来刻画,因而上述方法又可归为一类基于图的降维。之后,人们又将在支持向量机中关键的类间隔(Margin)思想引入其中,相应地发展出了近邻判别分析的降维算法(所谓类间隔是指类间的最小距离,直觉上,最大化该间隔能保证有好的判别性能)。与局部保持投影等无监督方法不同,近邻判别分析不仅综合了类别信息,而且通过同时构建类内及类间k近邻关系图定义出优化目标,进而优化该目标,以获得具有良好判别能力的数据降维。最近,严(S.Yan)等人提出的图嵌入的一般降维框架成为了一个典型的范例,它将上述多数降维方法纳入到该框架之中。在基于图的嵌入降维方法中,图的构建和参数的选取是其非常关键的步骤。

下面介绍几种投影降维方法
2.PCA 主成分分析
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。
2.1 原理:
PCA是一种把握事物主要性质的多元统计分析方法。它将原始变量变换为一小部分反映事物主要性质的变量(称之为主分量),从而将高维数据投影到了低维空间,并且保证投影后的低维数据在最小平方意义下最优地表征原有高维数据。
 |
 |
|---|---|
它具有如下性质:
- 保留方差是最大的
- 首先需要选择一个好的超平面。先看下图的例子,需要将2D降为1D,选择不同的平面得到右图不一样的结果,第1个投影以后方差最大,第3个方差最小,选择最大方差的一个感觉上应该是比较合理的,因为这样能保留更多的信息。
- 另外一种判断的方式是:通过最小化原数据和投影后的数据之间的均方误差。
- 最终的重构误差(从变换后回到原始情况)是最小的

2.2 算法步骤
主要步骤如下:
(1)计算数据样本的协方差矩阵;
(2)求解该协方差矩阵的特征向量,按照相应的特征值从大到小排序,选择排在前面的部分特征向量作为投影向量;
(3)将原高维数据投影到子空间中以达到降维的目的,即将数据转换到上述N个特征向量构建的新的空间中
补充资料:协方差矩阵计算公式:

两个特征的协方差计算例子:1
2
3
4
5
6
7Xi 1.1 1.9 3
Yi 5.0 10.4 14.6
E(X) = (1.1+1.9+3)/3=2
E(Y) = (5.0+10.4+14.6)/3=10
E(XY)=(1.1×5.0+1.9×10.4+3×14.6)/3=23.02
Cov(X,Y)=E(XY)-E(X)E(Y)=23.02-2×10=3.02
- 协方差矩阵的特征值和特征向量计算:
一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
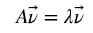
其中A为方阵,v 是特征向量,λ是特征值。λ为特征向量 v 对应的特征值。
特征值分解是将一个矩阵分解为如下形式:
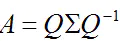
Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角矩阵,每一个对角线元素就是一个特征值,里面的特征值是由大到小排列。特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么
2.3 代码实现
numpy中实现PCA1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import numpy as np
#读取文件
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float,line) for line in stringArr]
return mat(datArr)
def pca(dataMat, topNfeat=n):
meanVals = np.mean(dataMat, axis=0)
#(axis=0)按列求均值
meanRemoved = dataMat - meanVals
#减去均值
covMat = np.cov(meanRemoved, rowvar=0)
#计算协方差矩阵,rowvar为0,
#一行为一个样本,不为0一列为一个样本
eigVals,eigVects = np.linalg.eig(mat(covMat))
#求特征值和特征向量,
#特征向量是按列放的,即一列代表一个特征向量 。
#eigVals以行向量形式存放特征值。
#eigVects存放特征向量,每一列代表一个特征向量。
eigValInd = np.argsort(eigVals)
#对特征值从小到大排序 ,函数argsort()返回从小到大排序的index
eigValInd = eigValInd[:-(topNfeat+1):-1]
#列表逆序以后,从头到位取前topNfeat个特征值index,
#即最大的n个特征值的index (python里面,list[a:b:c]代表从下标a开始到b,
#步长为c。list[::-1]可以看作是列表逆序)
redEigVects = eigVects[:,eigValInd]
#最大的n个特征值对应的特征向量
lowDDataMat = meanRemoved * redEigVects
#低维特征空间的数据
reconMat = (lowDDataMat * redEigVects.T) + meanVals
#把数据转换到新空间
return lowDDataMat, reconMat
调用sklearn中的PCA

sklearn.PCA参数说明:
- n_components:
意义:PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n
类型:int 或者 string,缺省时默认为None,所有成分被保留。 - copy:
类型:bool,True或者False,默认为True。意义:表示是否在运行算法时,将原始训练数据复制一份。若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算。 - whiten:
类型:bool,默认为False
意义:白化,使得每个特征具有相同的方差。就是对降维后的数据的每个特征进行归一化,一般不需要白化。
PCA对象的属性:
- components_ :返回具有最大方差的成分。
- explained_variance_:所保留的n个成分各自的方差
- explained_variance_ratio_:返回 所保留的n个成分各自的方差百分比。
- n_components_:返回所保留的成分个数n。
- noise variance:噪声方差大小
- mean_:特征均值
PCA对象的方法:
- fit(X,y=None)
fit()是scikit-learn中通用的方法。因为PCA是无监督学习算法,此处y等于None。
fit(X),表示用数据X来训练PCA模型。 - fit_transform(X)
用X来训练PCA模型,同时返回降维后的数据。 - inverse_transform()
将降维后的数据转换成原始数据,X=pca.inverse_transform(newX) - transform(X)
将数据X转换成降维后的数据。
2.4 PCA小结
作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA的一些缺点,出现了很多PCA的变种,比如为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
PCA算法的主要优点有:
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素。
- 计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
3. T-SNE(t-分布邻域嵌入算法)
t-Distributed Stochastic Neighbor Embedding (t-SNE) ,简单来说是一种「降维」的计算方法,同时也可以用于展示(可视化)高维数据。
3.1 基本原理
SNE是通过仿射(affinitie)变换将数据点映射到概率分布上,主要包括两个步骤:
- SNE构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有较低的概率被选择。
- SNE在低维空间里在构建这些点的概率分布,使得这两个概率分布之间尽可能的相似。
我们看到t-SNE模型是非监督的降维,他跟kmeans等不同,他不能通过训练得到一些东西之后再用于其它数据(比如kmeans可以通过训练得到k个点,再用于其它数据集,而t-SNE只能单独的对数据做操作,也就是说他只有fit_transform,而没有fit操作)
3.2 算法流程
有空再补
3.3 代码实现
1 | |
TSNE()这个函数里各个参数的含义:
- n_components:你想要降成几维,一维填1、二维填2、三维填3,没有别的选择了。
- perplexity:你的资料量越大,就越大。预设是30,建议值是5-50,但你可以不要采纳。
- n_iter:你想要迭代的次数,预设是1000。
- init:最初投影,两个选择“random” 或是“pca” (t-SNE里面有PCA噢!)
- verbose:要不要看训练过程
- random_state:控制随机数的生成
- method:不用改,除非你的数据量很小,才改成“exact”
执行完之后应该会出现两张图:
 |
 |
|---|---|
3.4 PCA vs. T-SNE
PCA和T-SNE同为降维工具,主要区别在于:机制和原理不同
T-SNE 运行极慢,PCA 则相对较快;
因此通常来说,T-SNE只能用于展示(可视化)高维数据,由于速度慢常常先用 PCA 进行降维,再使用 tsne:
1 | |
4. MDS:多维标度法
MDS类似T-SNE,经常用于数据可视化,维度大多是时候是2-3,他在降维的同时尽可能保留样本间的相对距离。
具体介绍略….直接看代码…
1 | |
多维标度法解决的问题是:当n个对象(object)中各对对象之间的相似性(或距离)给定时,确定这些对象在低维空间中的表示,并使其尽可能与原先的相似性(或距离)“大体匹配”,使得由降维所引起的任何变形达到最小。
多维空间中排列的每一个点代表一个对象,因此点间的距离与对象间的相似性高度相关。也就是说,两个相似的对象由多维空间中两个距离相近的点表示,而两个不相似的对象则由多维空间两个距离较远的点表示。多维空间通常为二维或三维的欧氏空间,但也可以是非欧氏三维以上空间。
5. SVD 矩阵分解/奇异值分解
贝壳找房【语言模型系列】原理篇一:从 one-hot 到 Word2vec
Python机器学习笔记:奇异值分解(SVD)算法
⭐️Singular Value Decomposition as Simply as Possible
5.1. 原理
奇异值分解 (SVD) 是将矩阵 _A_ 进行分解,$A=UΣV^T$,其中 _A_ 是 _m_∗_n_ 的矩阵,_U_是 _m_∗_n_ 的矩阵,Σ 是 _m_∗_n_ 的矩阵,_V_ 是 _n_∗_n_ 的矩阵,如何求解得到这三个矩阵呢?
首先回顾一下特征值和特征向量的定义:
$Ax=λx$
其中,A 是 _m_∗_m_ 实对称矩阵,_x_ 是一个 _n_ 维向量,则称 _λ_ 是一个特征值,_x_ 是矩阵 _A_ 的特征值 _λ_ 对应的一个特征向量。如果我们求出了 _n_ 个特征值 $λ_1,λ_2…λ_n$及其对应的特征向量 $x_1,x_2…x_n$,如果这 _n_ 个特征向量线性无关,那么矩阵 _A_ 就可以表示为
$A=XΣX^{−1}$
其中,_X_ 是有 _n_ 个特征向量组成的 _n_∗_n_ 的矩阵,Σ 是由 _n_ 个特征值为主对角线的 _n_∗_n_ 维矩阵。一般会将 _X_ 进行标准化,即 $∣∣xi∣∣_2=1,x_ix_i^T=1,XX^T=I$,也就是得到了 $X^T=X^{−1}$,那么 _A_ 就可以表示为
$A=XΣX^T$
需要注意的是,直接进行特征分解的矩阵 _A_ 是方阵,而在 SVD 中的矩阵 _A_ 不一定是方阵,这时需要再做一些推导。
$AA^T=UΣV^TVΣ^TU^T$
由于 $V^TV=I$,所以
$AA^T=UΣ^2U^T$
因为$AA^T$是一个 _m_∗_m_ 的方阵,所以通过求解$AA^T$的特征向量,就可以得到矩阵 _U_。同理,通过求解$A^TA$的特征向量,就可以得到矩阵 _V_,通过对$AA^T$的特征值矩阵求平方根,就可以得到矩阵 _A_ 的奇异值矩阵 Σ。至此,我们得到了矩阵 A 的分解。
值得注意的是,奇异值是从大到小排列的,通常前 10% 甚至 1% 的奇异值的和就占了所有奇异值和的 99% 以上,奇异值在集合意义上代表了特征的权重,所以我们一般不会选择将整个 _U_ 矩阵作为词向量矩阵,而是选择前 k 维,最终的词向量表大小就是 _m_∗_k_ ,_m_ 是词表达小,_k_ 是词向量维度。
基于 SVD 的方法得到了稠密的词向量,相比于之前的 one-hot 有了一定提升,能够表现单词之间一定的语义关系,但是这种方法也存在很多问题:
- 矩阵过于稀疏。因为在构建共现矩阵时,必然有很多词是没有共现的
- 分解共现矩阵的复杂度很高
- 高频无意义的词影响共现矩阵分解的效果,如 is,a
- 一词多义问题,即同一个词具有不同含义却被表示为一个向量,比如 bank 既有银行的意思,也有岸边的意思,但在这里被表示为统一的向量
5.2. 使用
numpy中调用方式和求特征值特征向量类似。实际上特征分解是一种特殊的奇异值分解,特征分解只能分解方阵,奇异值分解可以分解任意矩阵,pca中的特征分解通常会使用svd。1
2import numpy as np
U,Sigma,VT = linalg.svd(matrix)
5.3. 降维
利用SVD降维实际上是用来简化数据,使用了奇异值分解以后仅需保留着三个比较小的矩阵,就能表示原矩阵,不仅节省存储量,在计算的时候更是减少了计算量。SVD在信息检索(隐性语义索引)、图像压缩、推荐系统等等领域中都有应用。【TruncatedSVD(截断SVD)】sklearn中的pca就是使用svd分解,再选取三个在矩阵中间的对角矩阵中最大的一部分值,再还原这个矩阵。
6. LDA 线性判别分析
PCA是一种无监督的数据降维方法,与之不同的是:LDA是一种有监督的数据降维方法。我们知道即使在训练样本上,我们提供了类别标签,在使用PCA模型的时候,我们是不利于类别标签的,而LDA在进行数据降维的时候是利用数据的类别标签提供的信息的。
从几何的角度来看,PCA和LDA都是将数据投影到新的相互正交的坐标轴上。只不过在投影的过程中他们使用的约束是不同的,也可以说目标是不同的。PCA是将数据投影到方差最大的几个相互正交的方向上,以期待保留最多的样本信息。样本的方差越大表示样本的多样性越好,在训练模型的时候,我们当然希望数据的差别越大越好。否则即使样本很多但是他们彼此相似或者相同,提供的样本信息将相同,相当于只有很少的样本提供信息是有用的。样本信息不足将导致模型性能不够理想。这就是PCA降维的目的:将数据投影到方差最大的几个相互正交的方向上。
由于PCA与LDA的动机不同,前者着眼于降维数据对原有高维数据保真度的优化,而后者更关心降维数据对不同类数据判别性的优化。因此对于相同的数据,它们求解出的投影方向(向量)也截然不同(见图1)。下图中,假设一组二维数据样本,分为两类(ClassⅠ与ClassⅡ),PCA选择方差最大的方向作为投影方向(图中以实线表示),目的是使得投影的数据能在最小平方意义下尽可能地表征原数据。这样做投影确实方差最大,但是是不是有其他问题。聪明的你发现了,这样做投影之后两类数据样本将混合在一起,将不再线性可分,甚至是不可分的。这对我们来说简直是地狱,本来线性可分的样本被我们亲手变得不再可分。而我们发现,如果使用图中虚线,向这条直线做投影即能使数据降维,同时还能保证两类数据仍然是线性可分的,这其实就是LDA的思想:不同类数据之间区别将被最大化,同类别样本之间的区别将达到最小化,从而显著提高了各类别之间的可分性。

LDA将带有标签的数据降维,投影到低维空间同时满足三个条件:
- 尽可能多的保留数据样本的信息(即选择最大的特征是对应的特征向量所代表的方向)。
- 寻找使样本尽可能好分的最佳投影方向。
- 投影后使得同类样本尽可能近,不同类样本尽可能远。
代码实现
References
【机器学习系统设计】
【机器学习—周志华】
【机器学习实战】
详解多维标度法(MDS,Multidimensional scaling)
《各类降维方法总结-简书》