对话系统之NLU
核心思路

意图识别NLU,一般作为多分类问题,需求是对给定query进行分类,找到最可能的主问题类别。
对话系统之NLU2.0,核心思路是以搜代分(检索+排序):
离线:
- 训练一个语义相似度表征模型。
- 用表征模型预测每一个知识库内标准问的语义向量。
- 将语义向量入库,即存入检索es库中
在线(来了一个query请求):
- 用上面训练的表征模型预测query的向量。
- 通过传统检索方法召回top n候选集。
根据相似度完成对top n候选的排序。
离线
离线负责数据预处理、数据集构建、模型构建、模型训练、物料/索引问的向量预测、索引构建入库的核心操作,当然一些服务的基本配件,比如一键打包/部署的脚本、定时任务、日志、监控、校验等任务也会有
索引构建入库的2种方式:
切词,然后做倒排索引,即传统的search切词倒排索引模式
现在比较潮流的做法就是把文本转化为向量然后做成向量索引,即泛化程度较高的语义向量索引
语义相似度表征模型方案1:
- 采用 AM-Softmax,它是一种带margin的softmax,通常用于用分类做检索的场景
- 分类任务的目标是“最靠近所属类的中心”,而排序的目标是“类内差距小于类间差距”
- 为了保证分类模型的特征可以用于排序,那么每个样本不仅仅要最靠近类中心,而且是距离加上 $m$ 之后还要最靠近类中心,这便是带加性margin的Softmax的重要性!
- 最后,取CLS层输出,直接进行余弦相似度计算

语义相似度表征模型方案2:
- 分类相似性学习-Pointwise
即将句子相似度视为二分类模型(sigmoid接近1更相似); - 度量学习
即将句子相似度视为排序关系学习问题; - 采用Listwise的训练方式,如:ListNet
正负例采样
主问题+相似问+负采样多个
取度量模型的隐层进行ranking

语义相似度模型选择:
1、Poly-encoders
论文名称:ICLR 2020 | Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
arxiv地址:
https://arxiv.org/pdf/1905.01969.pdf
论文解读:
https://jishuin.proginn.com/p/763bfbd2cb83
解决双塔式交互不足以及交互式速度慢的问题!
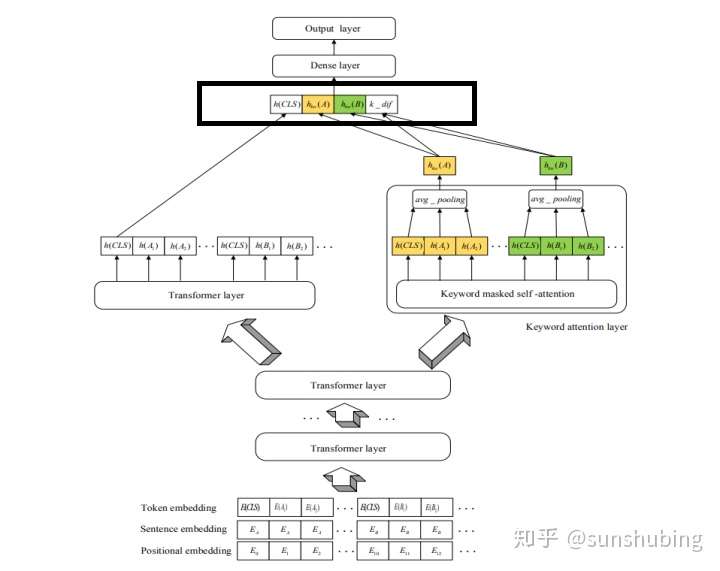
2、Keyword-BERT
论文名称:Keyword-Attentive Deep Semantic Matching
arxiv地址:https://arxiv.org/pdf/2003.11516.pdf
中文解读:基于关键字注意的深层语义匹配模型、远离送命题: 问答系统中语义匹配的『杀手锏』
Code: https://github.com/DataTerminatorX/Keyword-BERT/tree/master/keyword-bert
注意:如果我们不能提供足够的训练样本,去教会模型分辨出『关键信息』,光凭模型自身的花式 CNN/RNN/Attention,纵使使出浑身解数,在一些很难分辨的 case 上也未必work!!可以考虑 Keyword-BERT
本文的主要贡献如下:
- Keyword-attentive BERT:在 BERT 的最后一层引入一个额外的 keyword-attentive 层,目标是在注意力机制中强调关键词与非关键词之间的交互。通过明确地 “告诉” 模型哪些是重要的词,实验表明 Keyword-attentive BERT 优于原始 BERT。
- 更好的负采样训练更鲁棒的模型:提出了一种新的负采样方法,该方法采用 keyword 重叠分数来选择信息更丰富的负样本。此外,应用实体替换技巧来生成更多种类的负样本,比如将实体 “China” 替换成 “America”,经过数据增强,模型训练得更加鲁棒。
- Keyword 抽取:提出一种利用领域信息的简单有效的关键字提取算法,抽取出来的关键字可以在三个方面使用:a. 建立 keyword-attentive 深层语义匹配模型,b. 提高 QA 搜索引擎的召回质量,c. 改进负采样训练一个更好的语义匹配模型。
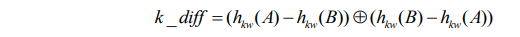
3、SimNet
服务地址:Paddle短文本语义匹配—SimNet
短文本语义匹配(SimilarityNet, SimNet)是一个计算短文本相似度的框架,可以根据用户输入的两个文本,计算出相似度得分。SimNet框架在百度各产品上广泛应用,主要包括BOW、CNN、RNN、MMDNN等核心网络结构形式,提供语义相似度计算训练和预测框架,适用于信息检索、新闻推荐、智能客服等多个应用场景,帮助企业解决语义匹配问题。可通过AI开放平台-短文本相似度线上体验。
同时推荐用户参考 IPython Notebook demo
在线
在线则有query/用户的向量预测、向量召回的工作(facebook开源的向量召回工具faiss等)。用户请求query输入,把它用离线训练好的模型转化为向量。之后通过传统检索召回一批和query字面相似的结果,经过一些规则并根据相似度进行排序,即可得到与之最接近的top主问题。除此之外,当然也有日志、监控、热更新、服务等其他算法服务也会有的工作。
NLU2.0 优缺点
优点是:
可控性强,准确率高
可以通过备选query的上下线来进行干预
把文本分类问题实质上转化为一个比较通用的相似度任务
语义相似度模型的构建相对简单,可以用外部数据进行训练,不需要领域内标注数据。
可以通过加备选query(别名)完成很多个分类的配置,从而实现多分类
对于样例数较少的类别比较友好,能够解决长尾问题?
但是也有缺点:
- 需要足量的备选query才能够实现较为精准的预测,缺少的话会影响召回。
Tips:
- 对于类目比较多的文本分类,我们可以把问题拆分,部分高频的可以用普通的文本分类来处理
- 对于长尾的,文本分类多分类其实很难处理,很容易学不到,因此就可以用文本检索的方式来处理