常见距离度量方法
在NLP中,我们经常要去比较两个句子的相似度,其标准方法是想办法将句子编码为固定大小的向量(Word2Vec、BERT等),然后用某种几何距离(欧氏距离、cos距离等)作为相似度。这种方案相对来说比较简单,而且检索起来比较快速,一定程度上能满足工程需求。
此外,还可以直接比较两个变长序列的差异性,比如编辑距离,它通过动态规划找出两个字符串之间的最优映射,然后算不匹配程度;
不同距离度量方法的图示

基于字符串💡
基于字符串的方法都是直接对原始文本进行比较, 主要包括编辑距离[11] (Levenshtein Distance, LD)、最长公共子序列[12] (Longest Common Sequence, LCS)、N-Gram[13] 和 Jaccard 相似度[14] 等.
基于字符串的方法原理简单、实现方便, 并且直接对原始文本进行比较, 多用于文本的快速模糊匹配, 其不足主要在于没有考虑到单词的含义及单词和单词之间的相互关系, 并且同义词、多义词等问题都无法处理.
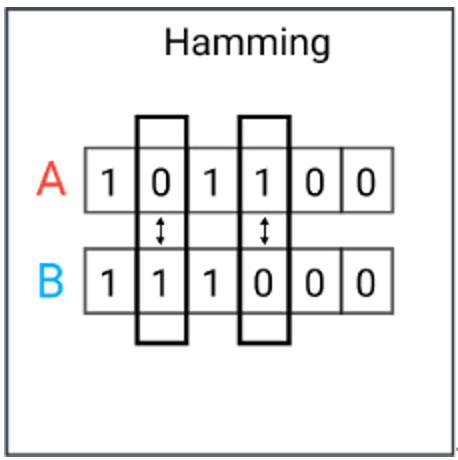
1. 汉明距离
汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量,比如:1011101 与 1001001 之间的汉明距离是 2;”toned” 与 “roses” 之间的汉明距离是 3。
1 | |
缺点
正如你所预料的,当两个向量的长度不相等时,汉明距离很难使用。你会希望将相同长度的向量相互比较,以了解哪些位置不匹配。
而且,只要它们不同或相等,它就不考虑实际值。因此,当幅度是一个重要的衡量标准时,不建议使用这个距离衡量。
用例
典型的使用情况包括在计算机网络上传输数据时的纠错/检测。它可以用来确定二进制字中的失真位数,以此来估计错误。
此外,你还可以使用汉明距离来测量分类变量之间的距离。
2. Levenshtein距离
莱文斯坦距离,又称编辑距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。
允许的编辑操作包括插入,删除和替换。莱文斯坦距离的应用:拼写检查、语音辨识、DNA分析、抄袭侦测。
1 | |
3. Jaro-Winkler距离
J-W距离(Jaro–Winkler distance)是两个字符串之间的另一个相似性度量。该算法对字符串中的字符串中的差异进行了惩罚。使用此算法的动机是,错字通常更有可能在字符串的后面而不是开头出现。比较”this test 和 test this”时,即使字符串包含完全相同的单词(只是顺序不同),相似度分数也仅为2/3。
Jaro–Winkler distance 是适合于如名字这样较短的字符之间计算相似度。0分表示没有任何相似度,1分则代表完全匹配。

其中,m是两个字符串匹配上的字符数目,t是字符中换位数目的一半,即若在字符串的第i位出现了a,b,在第j位又出现了b,a,则表示两者出现了换位。
PS:在该算法中,更加突出了前缀相同的重要性,即如果两个字符串在前几个字符都相同的情况下,它们会获得更高的相似性。
1 | |
4. Jaccard 相似度
Jaccard Similarity(或称交集比联合)度量两个字符串之间的共享字符,而不考虑顺序。公式是查找公用令牌的数量并将其除以唯一令牌的总数。
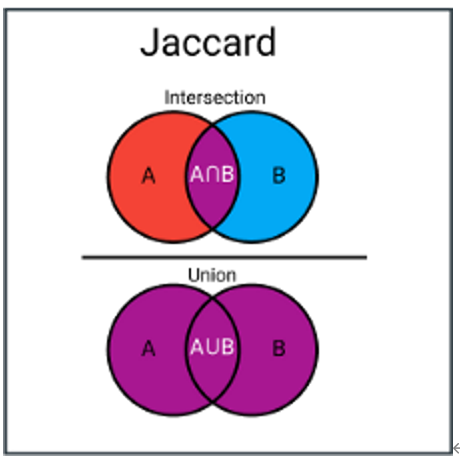
总结就是一句话:集合的交集与集合的并集的比例.
1 | |
1 | |
缺点
Jaccard指数的一个主要缺点是,它受数据大小的影响很大。大的数据集会对指数产生很大的影响,因为它可以在保持相似的交叉点的同时显著增加联合。
用例
Jaccard指数经常用于使用二进制或二值化数据的应用中。当你有一个深度学习模型预测图像的片段时,例如,一辆汽车,Jaccard指数就可以用来计算给定真实标签的预测片段的准确度。同样,它也可以用于文本相似性分析,以衡量文档之间的选词重叠程度。因此,它可以用来比较模式的集合。
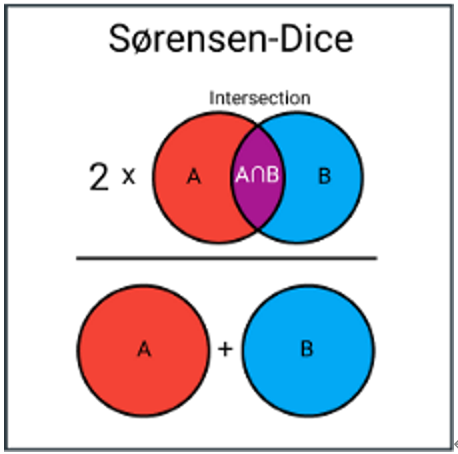
5. Sørensen–Dice coefficient
与 Jaccard 类似,Dice 系数也是一种计算简单集合之间相似度的一种计算方式。
1 | |
缺点
与Jaccard指数一样,它们都高估了集合的重要性,只有很少或没有TP(Truth Positive)值的正集合。因此,它可以求得多盘的平均分数。它将每个项目与相关集合的大小成反比加权,而不是平等对待它们。
用例
与Jaccard指数相似,通常用于图像分割任务或文本相似性分析。
6. 余弦相似度
余弦相似度是比较两个字符串的常用方法。该算法将字符串视为向量,并计算它们之间的余弦值。与上面的 Jaccard Similarity 相似,余弦相似度也忽略了要比较的字符串中的顺序。
1 | |

基于向量表示💡
1. 欧式距离
欧氏距离(L2范数/欧几里得度量/Euclidean Distance)指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)

numpy实现
1
2
3
4
5import numpy as np
def EuclideanDistance(vec1, vec2):
d = 1.0/(1.0 + np.linalg.norm(vec1-vec2, ord=2))
# d = 1.0/(1.0 + np.sqrt(np.sum(np.square(vec1-vec2))))scipy实现
1
2
3
4
5from scipy.spatial.distance import pdist
x=np.random.random(8)
y=np.random.random(8)
z=np.vstack([x,y])
d2=pdist(z)numpy实现(矩阵形式输入)
1
2
3
4
5
6
7
8
9
10
11
12
13
14def eucl_sim(self, s1_vec_ist, s2_vec_list):
A = np.array(s1_vec_ist)
B = np.array(s2_vec_list)
vecProd = np.dot(A, B.transpose())
SqA = A ** 2
sumSqA = np.matrix(np.sum(SqA, axis=1))
sumSqAEx = np.tile(sumSqA.transpose(), (1, vecProd.shape[1]))
SqB = B ** 2
sumSqB = np.sum(SqB, axis=1)
sumSqBEx = np.tile(sumSqB, (vecProd.shape[0], 1))
SqED = sumSqBEx + sumSqAEx - 2 * vecProd
SqED[SqED < 0] = 0.0
ED = np.sqrt(SqED)
ED = 1.0 / (1.0 + ED[0])缺点
虽然这是一种常见的距离测量方法,但欧几里得距离并不是尺度不变的,这意味着计算出的距离可能会根据特征的单位而有所偏斜。通常情况下,在使用这种距离测量之前,需要对数据进行归一化。
用例
当你有低维数据,并且向量的大小很重要,需要测量时,欧氏距离的效果非常好。如果在低维数据上使用欧氏距离,kNN和HDBSCAN等方法就会显示出很好的效果。
2. 曼哈顿距离
曼哈顿距离(L1范数/Manhattan Distance) 在欧几里得空间的固定直角坐标系上,两点所形成的线段对轴产生的投影的距离总和( 如棋盘 )。它们只能移动直角,且计算距离时不涉及对角线的移动。
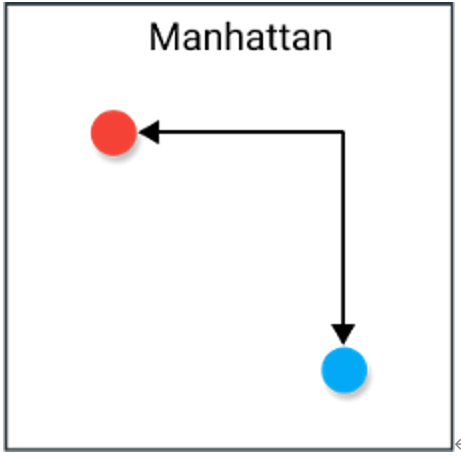
- numpy实现
1 | |
缺点
虽然曼哈顿距离对于高维数据似乎还不错,但它是一个比欧几里得距离更不直观的测量方法,尤其是在高维数据中使用时。
而且,它比欧几里得距离更容易给出一个更高的距离值,因为它不可能是最短路径。这不一定会带来问题,但你应该考虑到这一点。
用例
当你的数据集有离散和/或二进制属性时,曼哈顿似乎很好用,因为它考虑到了现实中在这些属性值内可以采取的路径。以欧氏距离为例,会在两个向量之间创建一条直线,而在现实中这可能实际上是不可能的。
3. 余弦相似度
算法描述
(1)使用词向量表示问句中的每一个单词;
(2)累加求平均词向量得句子的向量表示;
(3)最后计算两个向量之间角度的余弦作为相似度
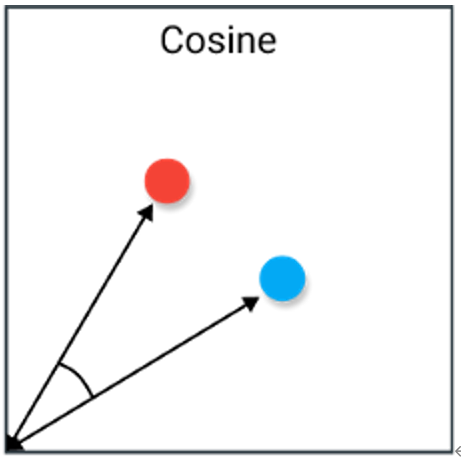

几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。余弦取值范围为[-1,1]。求得两个向量的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表征这两个向量的相似性。夹角越小,趋近于0度,余弦值越接近于1,它们的方向更加吻合,则越相似。
- numpy实现
1 | |
- numpy实现(矩阵形式输入)
1 | |
- Keras实现
1 | |
1 | |
缺点
余弦相似性的一个主要缺点是不考虑向量的大小,只考虑其方向。在实际应用中,这意味着值的差异没有被完全考虑。以推荐系统为例,那么余弦相似性并没有考虑到不同用户之间的评分等级差异。
用例
当我们有高维数据且向量的大小并不重要时,我们经常使用余弦相似度。对于文本分析来说,当数据用字数来表示时,这种测量方法是很常用的。
例如,当一个词在一个文档中出现的频率高于另一个文档时,这并不一定意味着一个文档与该词的关系更大。可能是文档的长度不均匀,计数的大小就不那么重要了。那么,我们最好是使用不考虑大小的余弦相似性。
PS:欧式距离和夹角余弦的区别
- 夹角余弦更能反映两者之间的变动趋势,两者有很高的变化趋势相似度;
- 而欧式距离较大是因为两者数值有很大的区别,即两者拥有很高的数值差异。
4. 修正余弦相似度
- 算法描述
修正cosine 减去的是对item i打过分的每个user u,其打分的均值
- numpy实现
1 | |
5. 皮尔森相关系数
皮尔森相关系数 (Pearson Correlation Coefficient) 是余弦相似度在维度缺失上面的一种改进方法,用于度量两个变量之间的相关程度 。实际上是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。
- numpy实现1
1 | |
- numpy实现2
1 | |
- numpy实现(矩阵形式输入)
1 | |
6. Word Mover’s Distance #
Word Mover’s Distance(WMD)(推词机距离?),大概可以理解为将一个句子变为另一个句子的最短路径,某种意义上也可以理解为编辑距离的光滑版。实际使用的时候,通常会去掉停用词后再计算WMD。
参考实现如下:
1 | |
7. Word Rotator’s Distance #
WMD其实已经挺不错了,但非要鸡蛋里挑骨头的话,还是能挑出一些缺点来:
1、它使用的是欧氏距离作为语义差距度量,但从Word2Vec的经验我们就知道要算词向量的相似度的话,用coscos往往比欧氏距离要好;
2、WMD理论上是一个无上界的量,这意味着我们不大好直观感知相似程度,从而不能很好调整相似与否的阈值。
为了解决这两个问题,一个比较朴素的想法是将所有向量除以各自的模长来归一化后再算WMD,但这样就完全失去了模长信息了。最近的论文《Word Rotator’s Distance: Decomposing Vectors Gives Better Representations》则巧妙地提出,在归一化的同时可以把模长融入到约束条件p,qp,q里边去,这就形成了WRD。
Word Rotator’s Distance(WRD)了。由于使用的度量是余弦距离,所以两个向量之间的变换更像是一种旋转(rotate)而不是移动(move),所以有了这个命名;同样由于使用了余弦距离,所以它的结果在[0,2][0,2]内,相对来说更容易去感知其相似程度。
参考实现如下:
1 | |
常用文本匹配库
textdistance 是一个用于比较两个或多个序列之间距离的Python库。它使用30多种不同的算法计算序列的距离,提供了可用于模糊匹配算法的集合.
python-Levenshtein 是一个快速计算Levenshtein距离和字符串相似度的模块。它能够快速计算出编辑距离以及编辑操作.
textdistance
textdistance包提供了可用于模糊匹配算法的集合,可以使用如下所示的pip来安装textdistance:
1 | |
但是,如果您希望从算法中获得最快的速度,则可以调整pip install命令,如下所示:
1 | |
安装完成后,我们可以像下面那样导入textdistance:
1 | |
All algorithms have some common methods:
.distance(*sequences)— calculate distance between sequences..similarity(*sequences)— calculate similarity for sequences..maximum(*sequences)— maximum possible value for distance and similarity. For any sequence:distance + similarity == maximum..normalized_distance(*sequences)— normalized distance between sequences. The return value is a float between 0 and 1, where 0 means equal, and 1 totally different..normalized_similarity(*sequences)— normalized similarity for sequences. The return value is a float between 0 and 1, where 0 means totally different, and 1 equal.
For example, Hamming distance:
1 | |
Any other algorithms have same interface.