语义文本相似度
简要介绍语义文本相似度计算的最新研究进展, 主要包括基于字符串、基于统计、基于深度学习的语义相似度计算方法。
1.基于字符串
基于字符串的方法都是直接对原始文本进行比较, 主要包括编辑距离[11] (Levenshtein Distance, LD)、最长公共子序列[12] (Longest Common Sequence, LCS)、N-Gram[13] 和 Jaccard 相似度[14] 等. 具体可参考《2021-05-26-常见距离度量方法》
基于字符串的方法原理简单、实现方便, 并且直接对原始文本进行比较, 多用于文本的快速模糊 匹配, 其不足主要在于没有考虑到单词的含义及单词和单词之间的相互关系, 并且同义词、多义词等问题都无法处理.
2.基于统计
基于统计的方法源于一种分布假设, 该假设认为上下文相似的单词具有相似的语义, 这类计算方 法先通过某种策略将文本转换成一个向量, 然后通过各种向量空间的转换, 最后计算表征文本的向量间距离, 通过向量空间中的度量来衡量文本间的相似度.
主流的基于统计的方法包括向量空间模型[17] (Vector Space Model, VSM) 和主题模型 (Topic Model), 而主题模型又可分为潜在语义分析模型[18] (Latent Semantic Analysis, LSA)、概率潜在语义分析模型[19] (Probabilistic Latent Semantic Analysis, PLSA) 和隐含狄利克雷分布模型[20] (Latent Dirichlet Allocation, LDA) 等.
2.1 基于向量空间模型
Salton 等[17] 在 1975 年首次提出向量空间模型 (VSM), 主要思想就是假设一个文本的语义只与该文本中的单词有关, 而忽略其语序和单词之间的相互关系, 然后通过基于词频统计的方法, 将文本映射成向量, 最后通过向量间的距离计算以表征文本间的相似度.
目前 VSM 中最常用的是基于 TF-IDF 的权重计算法(详细介绍可参考TF-IDF与余弦相似性的应用(二):找出相似文章), TF-IDF的分数代表了词语在当前文档和整个语料库中的相对重要性。TF-IDF 分数由两部分组成:第一部分是词语频率(Term Frequency),第二部分是逆文档频率(Inverse Document Frequency),计算方式如下:
1 | |
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以”词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。
- 代码示例如下(借助
Sklearn库)
1 | |
在利用 TF-IDF 权重计算法计算出各个特征项的权重之后, 就得到了可以表征文本的向量, 接下来只要计算向量之间的距离即可, 一般来说, 距离越近则两文本越相似.
2.2 基于主题模型
主题模型的基本假设是每个文档包含 多个主题, 而每个主题又包含多个单词. 换句话说, 文档的语义由一些隐变量表示, 这里的隐变量是指主题, 而这些主题代表了文档的语义信息. 而主题模型的目的就是揭示这些隐变量和它们之间的相互关系. 主题模型主要包括: ① 潜在语义分析 (LSA) 模型; ② 概率潜在语义分析 (PLSA) 模型; ③ 潜在狄 利克雷分布 (LDA) 模型.
潜在语义分析(LSA, Latent Semantic Analysis)5 的核心思想是将文本的高维词空间映射到一个低维的向量空间,我们称之为隐含语义空间。降维可以通过奇异值分解(SVD)实现.
2.3 基于概率模型
BM25 算法的全称为 Okapi BM25,是一种搜索引擎用于评估查询和文档之间相关程度的排序算法,其中 BM 是 Best Match 的缩写. BM25 算法是对 TF-IDF 算法的优化,在词频的计算上,BM25 限制了文档 D 中关键词 qi 的词频对评分的影响。为了防止词频过大,BM25 将这个值的上限设置为 k1+1。
首先我们来看一下bm25算法的计算公式:
我们来看看这个公式,首先Wi表示第i个词的权重,这里我们一般会使用TF-IDF算法来计算词语的权重,我在之前的博文对TF-IDF的理解与数学推导中,对TF-IDF算法有详细地分析与介绍,大家可以阅读参考。这个公式第二项R(qi,d)表示我们查询query中的每一个词和文章d的相关度,这一项就涉及到复杂的运算,我们慢慢来看。一般来说Wi的计算我们一般用逆项文本频率IDF的计算公式:
在这个公式中,N表示文档的总数,n(qi)表示包含这个词的文章数,为了避免对数里面分母项等于0,我们给分子分母同时加上0.5,这个0.5被称作调教系数,所以当n(qi)越小的时候IDF值就越大,表示词的权重就越大。我们来举个栗子:“bm25”这个词只在很少一部分的文章中出现,n(qi)就会很小,那么“bm25”的IDF值就很大;“我们”,“是”,“的”这样的词,基本上在每一篇文章中都会出现,那么n(qi)就很接近N,所以IDF值就很接近于0,接着我们来看公式中的第二项R(qi,d),我们首先来看看第二项的计算公式:
在这个公式中,一般来说,k1、k2和b都是调节因子,k1=1、k2=1、b = 0.75,qfi表示qi在查询query中出现的频率,fi表示qi在文档d中出现的频率,因为在一般的情况下,qi在查询query中只会出现一次,因此把qfi=1和k2=1代入上述公式中,后面一项就等于1,最终可以得到:
我们再来看看K,在这里其实K的值也是一个公式的缩写,我们把K展开来看:
在K的展开式中dl表示文档的长度,avg(dl)表示文档的平均长度,b是前面提到的调节因子,从公式中可以看出在文章长度比平均文章长度固定的情况下,调节因子b越大,文章长度占有的影响权重就越大,反之则越小。在调节因子b固定的时候,当文章的长度比文章的平均长度越大,则K越大,R(qi,d)就越小。我们把K的展开式带入到bm25计算公式中去:
在我们了解了bm25算法的原理了之后,我们再一起学习一下用Python来实现它,参考使用sklearn的TfidfVectorizer实现OKapi BM25
- 个人代码实现
1 | |
如果想更深入的了解BM25的理论基础,推荐阅读https://leovan.me/cn/2020/10/text-similarity/;想要了解基本实现代码,可以参考 Implementation of OKapi BM25 with sklearn’s TfidfVectorizer
小结
传统的文本匹配技术主要有Jaccard、Levenshtein、Simhash、TF-idf、Bm25、VSM等算法,其主要是基于统计学方法通过词汇重合度来计算两段文本的字面相似度。然而,仅通过字面相似度是衡量文本的匹配度是远远不够的,因为同一语义的文本在形式上千变万化,两段文本可以表现为字面相似但词序不同而导致语义完全相反;可以表现为字面相似但个别字词不同而导致意思大相径庭;更可以表现为字面完全不相似而语义相同等问题。所以,传统的匹配算法存在着词义局限、结构局限等问题。
3.基于深度学习
3.1 分布式词向量
简单地说, 词向量技术就是将单词映射成向量, 最早出现的 one-hot 编码和 TF-IDF 方法都可以 将单词映射为向量. 但是, 这两种方法都面临维度灾难和语义鸿沟问题. 分布式词向量可以在保存更多语义信息的同时降低向量维度, 在一定程度上可以克服维度灾难和语义鸿沟问题.
Mikolov 等[55] 提出的 word2vec 是最早生成分布式词向量的方法, 它包含两个模型, 分别为 CBOW 和 Skip-gram, 基本思路是确定中心词和上下文窗口大小, CBOW 是通过上下文来预测中心词, Skipgram 是通过中心词来预测上下文, 整体来说是通过自监督训练的模型生成词向量. word2vec 的主要 问题在于它只能考虑局部信息, 局部信息的大小取决于上下文窗口的大小.
Pennington 等[56] 提出 Glove 模型, 该模型通过语料库构建单词的共现矩阵, 然后通过该共现矩阵 用概率的思想得到最终的词向量, 综合了全局语料, 在一定程度上考虑了全局信息.
Joulin 等[57] 则是提出了一种快速文本分类方法 FastText, 其同样可以用于生成词向量, 模型架构 与 CBOW 类似, 但赋予模型的任务不同. CBOW预测上下文的中间词,fasttext预测文本标签。与word2vec算法的衍生物相同,稠密词向量也是在训练神经网络的过程中得到的。fasttext的python实现
以上 3 种词向量为静态词向量, 即当它们应用于下游任务时词向量始终是固定的, 无法解决一词 多义问题, 同时无法满足不同语境下语义不同的场景需求.
动态词向量则是为了解决上述问题所提出的, 这类词向量首先在大型语料库上进行预训练, 然后在面对具体下游任务时微调所有参数, 那么在上下文输入不同时, 生成的词向量也不同, 因此可以解 决一词多义问题.
Peters 等[58] 提出 ELMO 模型, 其使用双向语言模型和两个分开的双层 LSTM 作为编码器, 通过 在大型语料库上进行预训练得到动态词向量.
Radford 等[59] 提出 GPT 模型, 通过将单向语言模型与编码能力更强大的 Transformer[60] 架构的 decoder 部分相结合, 从而生成词向量.
Devlin 等[61] 提出的 BERT 模型, 则是应用 Transformer[60] 的 encoder 部分, 结合 mask 机制, 并且对模型增加了预测“next sentence prediction”任务, 从而生成了更加优质的动态词向量, 该模型也是目前最常用的词向量预训练方法之一. 要是想使用BERT作为服务,具体实现过程可以参考博客《bert_as_service使用指南》)
3.2 基于无监督学习方法的语义文本相似度计算
无监督学习方法不需要带有标签的数据集就可以计算文本间的语义相似度, 减少了人工打标签的成本, 并且更加通用
https://cloud.tencent.com/developer/article/1155863
Le 等[62] 在 word2vec[55] 的启发下提出了 doc2vec. 该模型在训练词向量的同时, 加入表征段落的向 量和词向量共同训练. doc2vec 与 word2vec 相同, 有两种训练方式, 一种是通过段落向量和上下文单 词向量预测中心词; 另一种则是通过段落向量预测文本中包含的单词. 这样就可以通过计算训练好的 段落向量之间的余弦值表征其语义文本相似度. gensim库提供了doc2vec的实现.
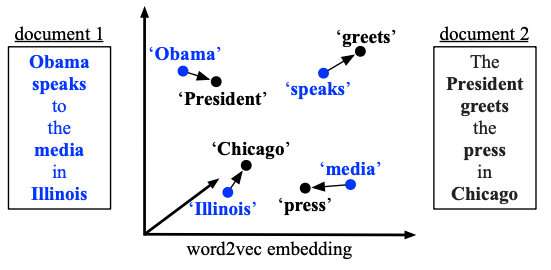
Kusner 等[67] 将句子相似度问题转换为运输问题, 引入词移距离, 将文本间距离转化为约束条件下 的最优化问题, 巧妙地将运输问题中的 EMD 算法应用到相似度计算当中, 得到了 WMD 算法. 简单来说,用句子A走到句子B的最短距离来衡量两者的相似程度。表示在下图中就是非停用词的向量转移总距离:
Arora 等[68] 提出的 SIF 算法则是将主成分分析 (PCA) 用于句向量的生成, 首先用通过改进的 TFIDF 方法对词向量进行加权平均得到句向量, 然后减去所有句子向量组成的矩阵的第一个主成分上的投影, 得到最终的句子嵌入. 实验表明该方法具有不错的竞争力, 在大部分数据集上都比平均词向量或者使用 TFIDF 加权平均的效果要好.
3.3 基于监督学习方法
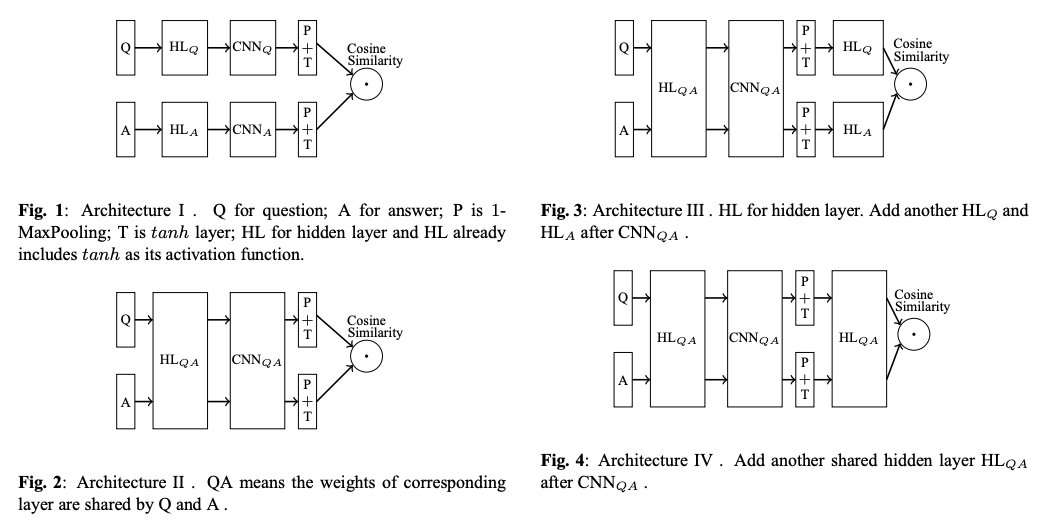
监督学习方法是一类需要带有标签的训练集对模型进行训练后才能进行语义文本相似度计算的 方法, 这类方法由于有标签对模型进行指导, 在多数有训练集的任务上, 其性能要优于无监督学习方 法. 监督学习方法从模型架构上可以分为两种, 一种是孪生网络 (Siamese Network) 架构; 另一种是交互 (interaction-based) 模型架构, 两种模型的典型架构如图所示.

孪生网络架构主要体现在句子对中$S_A$和$S_B$同时输入左右两个网络当中, 这两个网络的输入层和编码层模型架构完全相同并共享权重,通过余弦相似度等方式来计算query间的相似度,不断最大化正样本之间的相关性,抑制负样本之间的相关性;双塔式更侧重对表示层的构建
交互模型如图 2b) 和图 2c) 所示, 整体与孪生网络类似, 但在编码层利用 Attention 机制或其他技术增加两个网络间的交互,交互式模型通常使用二分类的任务来进行训练,当模型输入的两个query语义一致,label为“1”,反之,label为“0”。在预测时,可通过logits来作为置信度判断。
两种框架比较的话,
- 基于表示的匹配方法优势在于Doc的语义向量可以离线预先计算,在线预测时只需要重新计算Query的语义向量速度会快很多;缺点是模型学习时Query和Doc两者没有任何交互,不能充分利用Query和Doc的细粒度匹配信号。
- 基于交互的匹配方法优势在于Query和Doc在模型训练时能够进行充分的交互匹配,语义匹配效果好,缺点是部署上线成本较高。
二者在Similarity measure layer的匹配度函数f(x,y)计算,通常有两种方法:一种是通过相似度度量函数进行计算,实际使用过程中最常用的就是 cosine 函数,这种方式简单高效,并且得分区间可控意义明确;另一种方法是将两个向量再接一个多层感知器网络(MLP),通过数据去训练拟合出一个匹配度得分,更加灵活拟合能力更强,但对训练的要求也更高。
语义表征模型常用于海量query召回,交互式模型更多使用于语义排序阶段
3.3.1 基于孪生网络的方法
它的优势是结构简单、解释性强,且易于实现,是深度学习出现之后应用最广泛的深度文本匹配方法。整个学习过程可以分为两步:① 表示层:计算 query 和 doc 各自的 representation;② 匹配层:根据上一步得到的 representation,计算 query-doc 的匹配分数。
DSSM
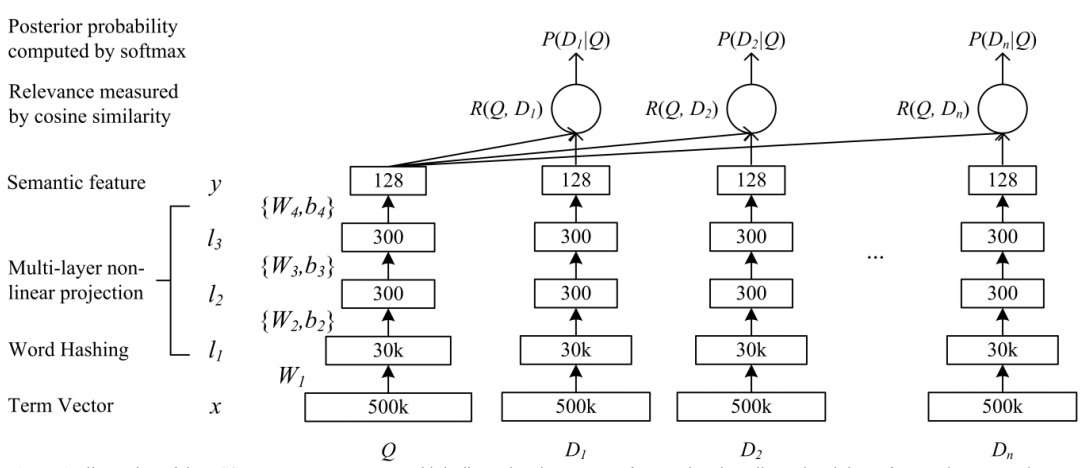
DSSM 算法是最先将孪生网络架构用于语义文本相似度计算的算法之一, DSSM 架构主要分为输入层、表示层、匹配层, 这种三层架构也是后来基于孪生网络的算法最常用的 架构. 输入层主要将原始文本映射为向量, 由于本文在 2013 年被提出, 当时的分布式词向量刚刚问世, 因此本文并没有使用词向量, 而是使用字符级的 trigram 方法将文本映射为高维向量, 更具体地说, trigram 是将 3 个字符为一组映射为 one-hot 向量, 最后将句子中的 trigram 向量相加得到高维句子向 量表示. 表示层是将高维的句子向量映射为低维向量, DSSM 表示层就是简单的几个全连接层, 最终 将句子映射为 128 维的低维向量. 匹配层是将两个低维句子向量表示之间求余弦相似度来表征两个句子的语义相似度. DSSM模型在文本匹配任务上取得了突出的成绩, 但忽略了语序信息和上下文信息.
ARC-I
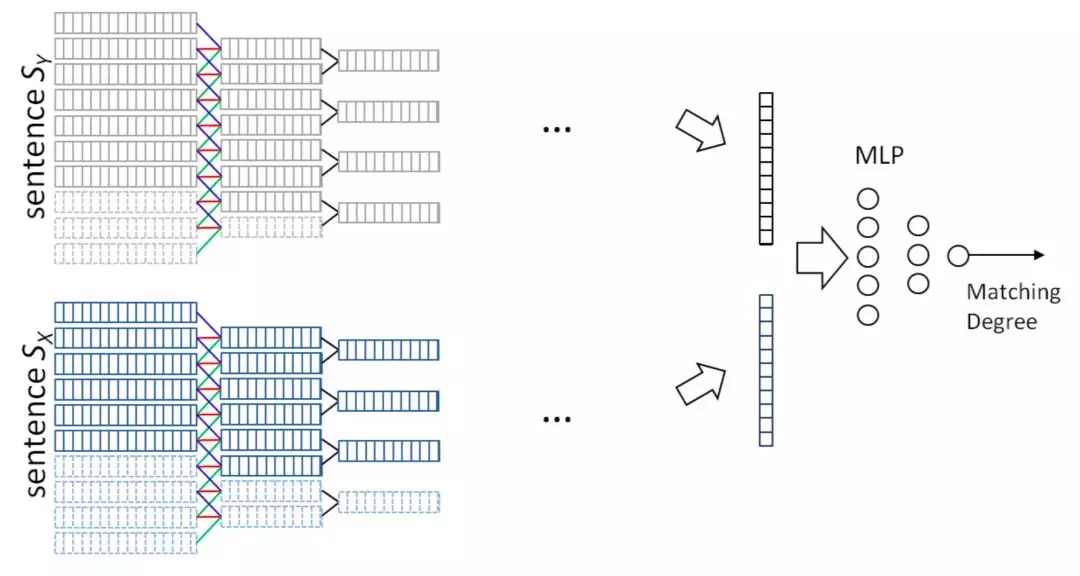
针对上述讲到的 DSSM 模型对 query 和 doc 序列和上下文信息捕捉能力的不足,华为诺亚方舟在 2015 年在 DSSM 的模型基础上加入了 CNN 模块,通过卷积层不同的 feature map 来得到相邻 term 之间的多种组合关系,通过池化层 max pooling 来提取这些组合关系中最重要的部分,进而得到 query 和 doc 各自的表示。卷积层虽然提取到了 word-ngram 的信息,但是池化层依然是在局部窗口进行 pooling,因此一定程度上无法得到全局的信息。
Siam-CNN
1 | |
在2015年IBM提出的Siam-CNN架构中,作者尝试了多种孪生架构,使用CNN作为基础编码器,hinge loss作为损失函数. 该方法对DSSM的改进主要发生在表示层, 该模型表示层中添加了卷积层和池化层, 使得上下文信息得到了有效保留, 但是由于卷积核的限制, 距离较远的上下文信息仍会丢失. 最后实验发现第二种是最好的.
PS: During training, for each training question Q there is a positive answer A +(the ground truth). A training instance is constructed by pairing this A + with a negative answer A −(a wrong answer) sampled from the whole answer space
Siam-LSTM
1 | |
2016年的Siam-LSTM在结构上比较简单,就是直接用共享权重的LSTM编码,取最后一步的输出作为表示。有个改进点是作者使用了Manhattan距离计算句子对的语义相似度. 实验证明将该方法和SVM结合用于情感分类(Entailment Classification), 效果提升明显.
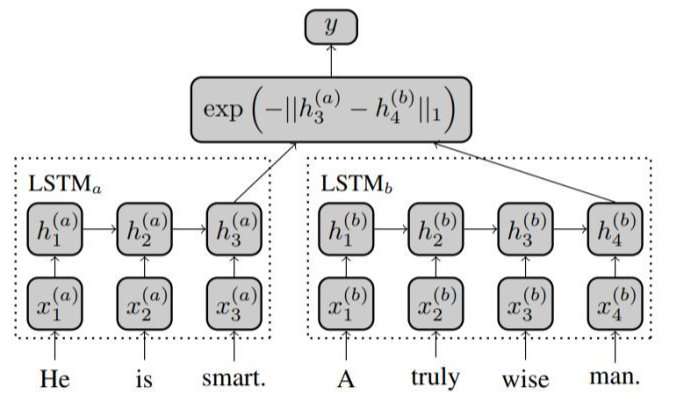
BiLSTM+Self-Attention
Lin等[A structured self-attentive sentence embedding] 将双向LSTM(BiLSTM)和Self-Attention技术相结合得到句子向量表示, 具体来说就是, 首先将句子通过BiLSTM模型, 将得到的每一时刻的两个方向的向量拼接成一个二维矩阵, 然后通过自注意力机制(Self-Attention)[60]得到句中每个词向量对应的权重, 最终通过词向量的加权求和得到句向量. 在训练网络时同样是使用Siamese架构, 在得到句向量后进行简单的特征提取, 如拼接、点积、对位相减等, 然后输入一个多层感知机, 得到最终的语义文本相似度.

Sentence-BERT
1 | |
EMNLP2019的Sentence-BERT是目前最常用的BERT式双塔模型,一是效果真的好,二是作者的开源工具做的很方便,用的人越来越多。
Sentence BERT(Sbert) 网络是通过 SNLI 数据集(标注了一对句子之间的关系,可能是蕴含、矛盾或者中立)进行预训练。首先将第一个句子输入到BERT,通过不同的Pooling方法获得句子的Embedding表示,第二个句子同样如此,然后将这两个Embedding变换后通过Softmax输出这对句子之间关系的概率进行训练(类似分类问题)。最后,获取pooling层的输出用于句子之间的余弦相似度计算和推理。SBert的网络结构:

- 在评估测试阶段,SBert直接使用余弦相似度来比较两个句向量之间的相似度,极大提升了推理速度;
1 | |
SBert开源地址:https://github.com/UKPLab/sentence-transformers
SBert多语预训练模型下载地址:https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/
小结
纵览上述方法, 可以清晰地看到基于孪生网络的计算方法的发展进程, 对于模型的改进主要集中在使用不同的编码器, 如从最开始的多层感知机发展为 CNN、LSTM, 再到 Transformer 等.
对速度要求高的召回场景可以用BOW+MLP、CNN,精度要求高的排序场景可以用LSTM、Transformer。同时两个向量的融合方法以及loss也都可以优化,比如做一些轻微的交互、像Deformer一样前面双塔接后面的多层交互,或者根据需要选择pointwise、pairwise(排序场景)损失。
但真要想做句间关系SOTA的话,比如刷榜,光靠双塔模型还是不行的,它有两个问题比较大:
- 位置信息。如果用BOW的话“我很不开心”和“我不很开心”两句的意思就变成一样了,虽然用RNN、BERT引入位置编码可以减缓一些,但不去让两个句子相互比较的话对于最后的分类层还是很难的
- 细粒度语义。比如“我开心”和“我不开心”这两句话只有一个字的区别,但BOW模型很可能给出较高的相似度,交互式模型则可以稍有缓解
3.3.2 基于交互模型的方法
基于孪生网络的方法在编码层对句子编码时是相互独立的, 句子对之间没有交互, 这样对于计算句子对的语义相似度会造成一定影响, 基于交互模型的方法就是为了解决这个问题而产生的, 它是在孪生网络的基础上增加两个平行网络之间的交互作用, 从而提取到句子对之间更加丰富的交互信息.
MatchPyramid
1 | |
MatchPyramid 模型的提出灵感源于 CV 领域里的图像识别。在此之前,文本匹配的维度是一维的 ( TextCNN 为代表的 word embedding );而图像是二维平面的,显然信息更加丰富。2016 年的 AAAI 上中科院提出了基于 word-level 级别交互的矩阵匹配思想,用一个二维矩阵来代表 query 和 doc 中每个 word 的交互。模型关键,在于如何构建 query 和 doc 中 word 级别的匹配信息,文章提出了匹配矩阵的 3 种构造方法,indicator、cosine 以及 dot product,分别如下:
indicator match
0-1 匹配矩阵,只有两个 word 完全相同才等于 1,否则为 0,相当于是精确匹配
cosine match
将每个 word 用 glove 预训练得到的词向量,两两计算 cosine 相似度
dot product match
将每个 word 用 glove 预训练得到的词向量,两两计算向量点积
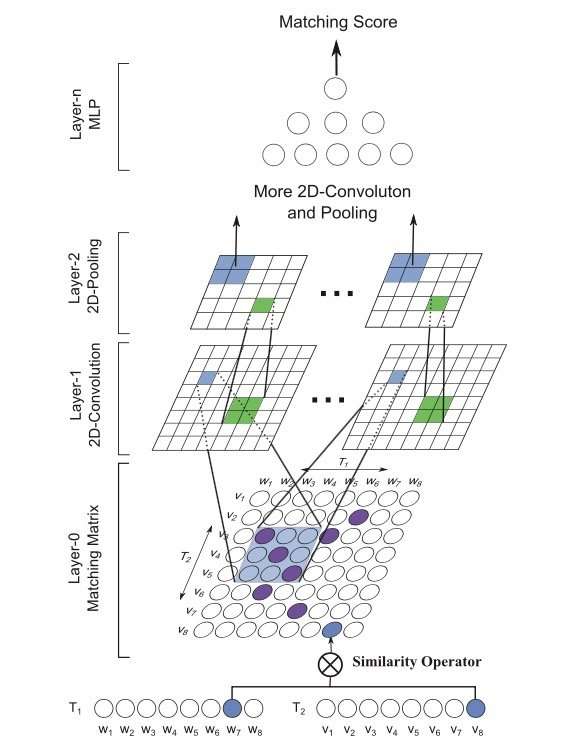
MV-LSTM
AAAI2016 年提出的 MV-LSTM 模型,用双向 LSTM 来对两段文本 query 和 doc 进行编码,然后将 LSTM 的每个隐层输出进行拼接作为 query 和 doc 每个 term 的输出,并对这些 term 两两计算匹配分数,得到不同维度的匹配度矩阵。最后,先用 k-max pooling 压缩特征,然后用 MLP 后输出最终的匹配分数。
整个模型可以分为 3 部分:① query 和 doc 各自的 LSTM 编码;② query 和 doc 的匹配矩阵;③ 匹配信号融合。文中提到了 cosine、双线性以及 tensor layer 这 3 种计算方法,由于网络参数的不断加大,拟合精确度和复杂度也依次提升:
cosine 相似度
query 中的 term u 以及 doc 中的 term v,计算 cosine 相似度 $s(u, v)=\frac{u^{T} v}{|u| \cdot|v|}$
双线性 bilinear
通过引入待训练参数 M 进行映射 $s(u, v)=u^{T} M v+b$
Tensor layer
$s(u, v)=\frac{u^{T} v}{|u| \cdot|v|}$

ABCNN
Yin等[79]提出了ABCNN模型, 是在词向量基础上通过CNN网络对句子进行处理, 在分别对句子对中的句子进行卷积和池化操作的同时, 使用Attention机制对两个中间步骤进行交互, 文中一共尝试了3种添加Attention的策略, 主要区别是作用于模型的不同阶段, 如第一种Attention是直接作用在词向量组成的矩阵上, 而第二种Attention是作用在经过卷积和池化操作后产生的输出矩阵上, 第三种则是将前两种方法相结合. 可以将经过卷积和池化操作后得到的结果看作短语向量, 而该短语向量的长度取决于卷积核的大小, 从这个角度理解, 第一种和第二种Attention方法的区别实质上是在不同粒度上对模型进行了处理.
PWIM
He等[80]通过BiLSTM对句子进行建模提出PWIM算法, 该方法共分为4个部分. 第一部分将BiLSTM网络每个时刻的输出, 即该时刻的双向hidden state做拼接获得的结果, 作为对应时刻word的representation. 第二部分通过计算两个句子的每个时刻的向量表示进行余弦相似度、欧式距离和点积计算, 然后根据计算结果来确定不同向量对的权重, 该方法认为句子内部不同的词的重要性是不一样的, 两个句子间重要的单词对, 对于句子相似度的计算贡献更大, 这些单词对应该得到更多的重视, 最后通过多层CNN网络得到最终结果.
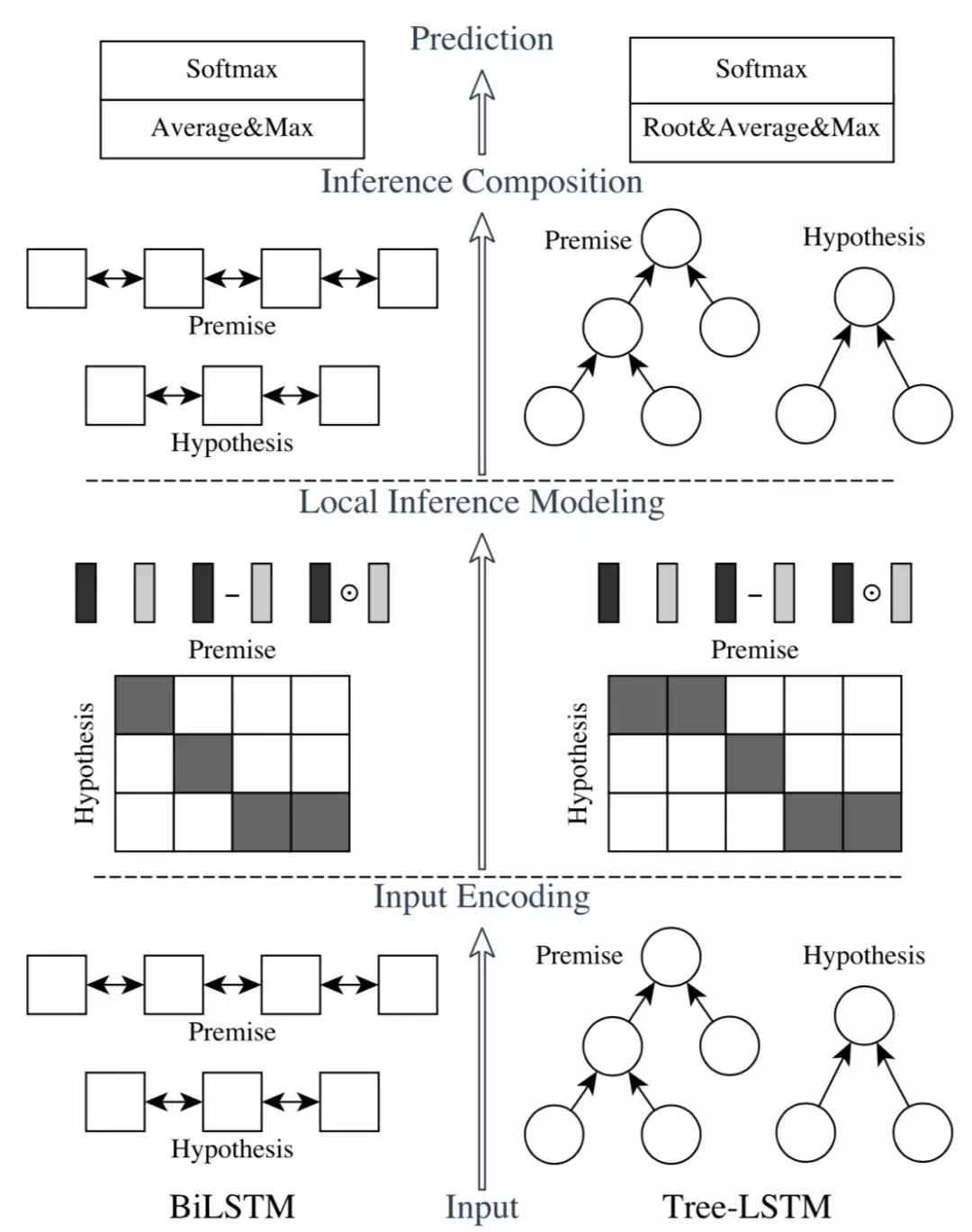
*ESIM
1 | |
ACL2017中的ESIM 模型在众多短文本匹配比赛中大杀四方,表现十分出色。ESIM 模型通过精细的序列式网络设计,以及同时考虑局部推断和全局推断的方法来达到更好的效果。它的计算过程有一下四步:
- 用BiLSTM对embedding编码,得到表示 $a,b$
- 将两句话的BiLSTM输出进行soft attention,得到融合的句子表示 $\alpha, \beta$
- 将 $[a, \alpha, a-\alpha, a \cdot \alpha]$ 拼接作为新表示,用BiLSTM再次编码,分别得到 $v_a,v_b$
- max+avg池化后过进行最终分类 $v=softmax(\left[v_{a, a v e} ; v_{a, m a x} ; v_{b, a v e} ; v_{b, m a x}\right])$
局部推理层是 ESIM 的点睛之笔, 主要就是用 attention 机制计算出 a 句某一单词和 b 句中各个单词的权重,然后再将权重赋予 b 句各个单词,用来表征 a 句中的该单词,形成一个新的序列,b 句亦然。
具体来说,使用点积的方式计算 a 句中第 i 个词和 b 句中第 j 个词之间的 attention 权重:
然后对两句各单词之间进行交互性计算,该词与另一句子联系越大,则计算出的值也会越大:
得到局部推断后,为了增强信息,分别使用了向量相减、向量点积。最终 4 个向量 concat 起来,$m_a$和$m_b$分别表示增强后的 premise 和 hypothesis。
PS:局部推理层中对于匹配矩阵的做法区别于使用 MLP 去提取 query 和 doc 两个句子的做法;而是用两种 LSTM 提取编码后计算加权向量表达。得到加权向量表达后,和原始向量进行乘积和相减后,总共 4 个向量 concat 起来,相当于是丰富了提取到的信息。同时,相比BIMPM,ESIM训练速度快,效果也并没有逊色太多
BIMPM
1 | |
IJCAI2017 年提出的同样基于BiLSTM网络提出双向多角度匹配模型BiMPM, 。该模型最大的创新点在于,对于给定的 query 和 doc,作者认为在匹配过程中,不仅需要考虑 query 到 doc,也应该考虑从 doc 到 query 的倒推关系,因此这是个双边 ( Bilateral ) 的关系。对于多角度,则是在考虑两个句子 query 和 doc 的关系的时候,用了 4 种不同的方法,体现了多角度 ( Multi-Perspective ) 的思想。BIMPM有着复杂的网络结构,计算复杂度高,很多计算之间又是串行的,可想而知,对于大规模的文本匹配计算速度很慢
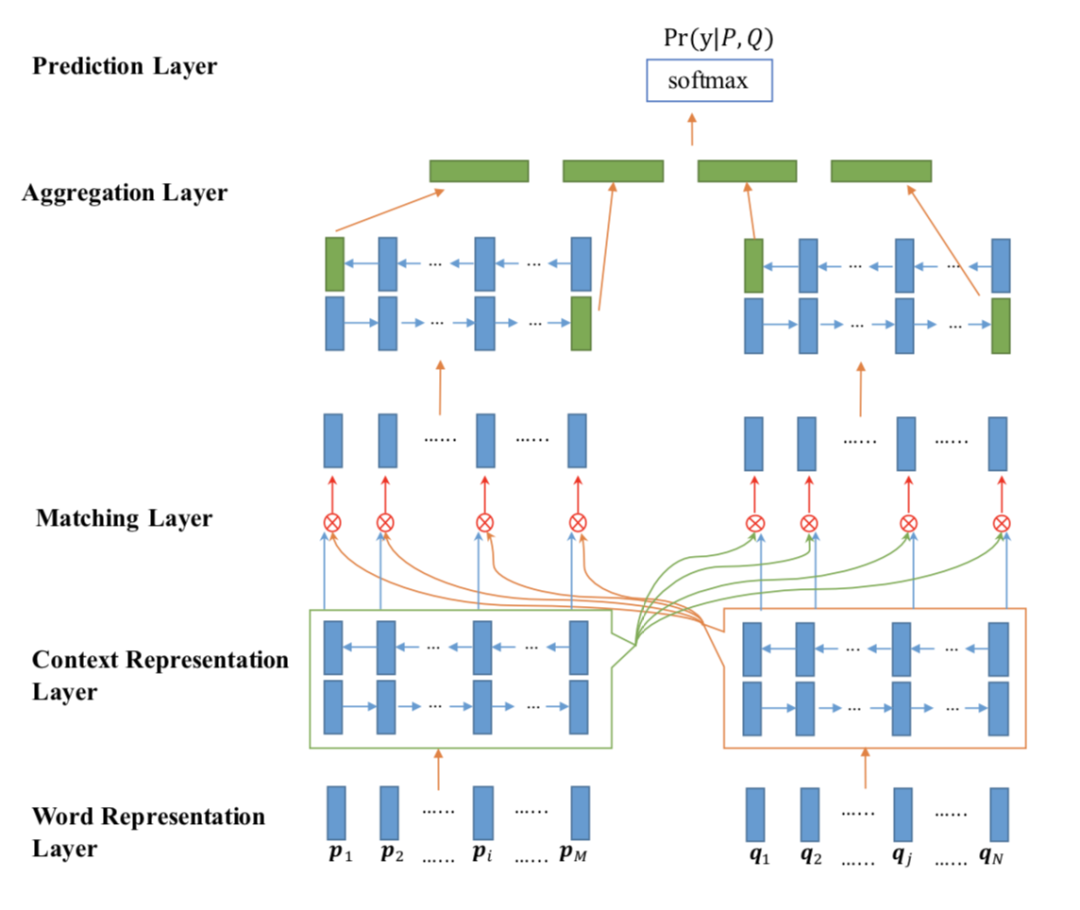
整个模型可以分为 5 层:① 词表示层;② 上下文表示层(使用词向量与字符向量的拼接);③ 匹配层;④ 聚合层(使用双向 LSTM将两个句子 P 和 Q 匹配得到的 16 个匹配向量(P->Q,Q->P 各 8 个),聚合成一个固定长度的匹配向量);⑤ 输出层(两层 MLP+softmax),其中匹配层为模型的核心,共提出了四种匹配策略,分别是:Full-Matching、Maxpooling-Matching、Attentive-Matching和 Max-Attentive-Matching:
- full-matching:在这种匹配策略中,用 P 中每一个 time step 的上下文向量(包含前向和后向)分别与句子 Q 中最后一个 time step 的上下文向量(包含前向和后向)计算匹配值,即
- maxpooling-matching:在第一种匹配方法中选取最大的匹配值,即
where $\max _{j \in(1 \ldots N)}$ is element-wise maximum.
- attentive-matching:先对 P 和 Q 中每一个 time step 的上下文向量(包含前向和后向)计算余弦相似度,得到相似度矩阵
然后将相似度矩阵作为 Q 中每一个 time step 权重,通过对 Q 的所有上下文向量(包含前向和后向)加权求和,计算出整个句子 Q 的注意力向量
最后,将 P 中每一个 time step 的上下文向量(包含前向和后向)分别与句子 Q 的注意力向量计算匹配值
- max-attentive-matching:与 attentive-matching 的匹配策略相似,不同之处在于选择句子 Q 所有上下文向量中余弦相似度最大的向量作为句子 Q 的注意力向量。
DIIN
1 | |
DIIN 模型是在 ICLR2018 上提出的, 输入层使用单词嵌入、字符特征和句法特征的串联, 编码层使用自注意力60机制, 交互层采用点积操作得到交互矩阵, 然后使用DenseNet[84]进行特征抽取, 之后将抽取的特征传入多层感知机模型得到最终的结果, 本方法简单有效, 在NLI任务上表现出很好的性能.
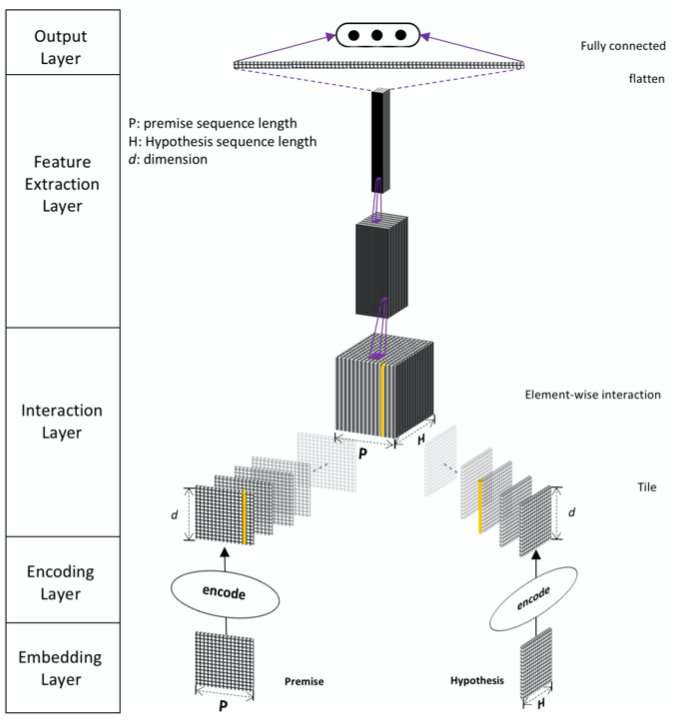
模型可以分为 5 个部分,分别是嵌入层、编码层、交互层、特征抽取层以及输出层:
- Embedding Layer
在 embedding 层中,论文中同时将单词级别 embedding、字符级别特征的 embedding (OOV)以及句法级别的特征 embedding 信息 (一个是词性特征 ( POS ),另一个是二进制精确匹配特征 ( EM )),全部concat 起来作为每个词的 embedding。
- Encoding Layer
Encoding Layer的主要作用是将上一层的特征进行融合并进行encode。论文中作者采用的是self-attention机制,同时考虑到了词序和上下文信息。以P作为例子,首先计算attetion matrix
这里的attention matrix的 计算方法和transformer的还不太一样,作者取了三个维度的值并拼接起来,如下面的公式所示,我的理解是a与b应该是一样的,因为都是针对的P,唯一多了个a ∘ b其中的∘是对位相乘,如果P的维度是d,那么拼接后的向量维度是3d
然后加上softmax计算self-attention的值
接下来作为引入了LSTM中门的概念semantic composite fuse gate,其计算公式如下
其中 W 的维度均是$[ 2 d , d ]$,b的维度是d,σ表示的是sigmoid函数
H的操作和P的操作一样,就不再赘述了,有一点需要注意,论文中认为P和H是有细微差距的,所以attention的权重和gate的权重是没有共享的,不过论文中的任务五是NLI,如果是相似度匹配的任务我觉得此处是可以共享的,必须相似度匹配两个句子本身就是很接近的,此观点仅代表个人想法没有验证过,代码中我们还是以论文为主。
- Interaction Layer
Interaction Layer的主要目的是把P与H做一个相似度的计算,提取出其中的相关性,可以采用余弦相似度、欧氏距离等等,这里作者发现对位相乘(向量点积)的效果很好,所以公式中的 $\beta(a, b)=a \circ b$
- Feature Extraction Layer
Feature Extraction Layer的任务正如其名,做特征提取。这一层论文主要采用的是CNN的结构,作者实验发现ResNet效果会好一些,但是最终还是选择了DenseNet,因为DenseNet能更好的保存参数,并且作者观察到ResNet如果把skip connection移除了模型就没法收敛了(ResNet的关键就在于skip connection不知道作者为什么要说明这一点)BN还会导致收敛变慢(这里应该是指针对当前这个模型来说)所以作者并没有采用ResNet。卷积采用的是relu激活函数,都是1×1的卷积核来对上文提到的相关性tensor进行缩放,并且这里引入了一个超参数η,例如输入的channel是k那么输出的channel就是k × η,然后把结果送到3层Dense block中,Dense block包含了n个3×3的卷积核,成长率是g,transition layer采用了1×1的卷积核来做channel的缩减,然后跟上一个步长为2的最大池化层,transition layer的缩减率用θ表示。这一层的关键就在于DenseNet,对DenseNet不清楚的小伙伴一定要先去了解该网络的结构原理,这也是为啥作者会把该模型取名为Densely Interactive Inference Network
- Output Layer
输出层使用简单的一个线性层以及 softmax 多分类进行分类。
HCAN
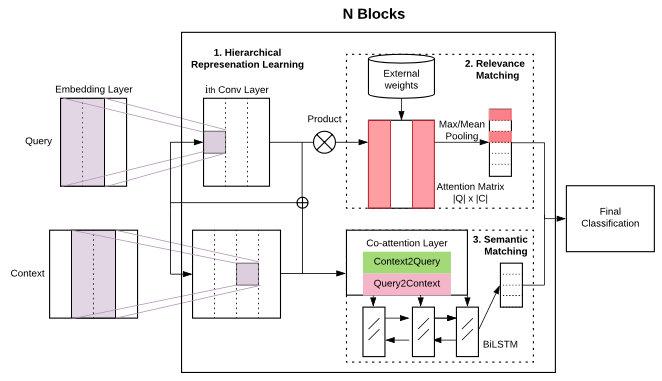
1 | |
HCAN是Facebook在EMNLP2019提出的模型,虽然比上文的ESIM、PWIM等模型高上4+个点,但还是被BERT甩了很远。不过这个模型的核心也不只是做语义匹配,而是同时做检索相关性(Relevance Matching),也就是搜索中query-doc的匹配。
模型计算如下:
- Encoding层作者提出了三种方法,堆叠的CNN作为Deep Encoder,不同尺寸卷积核作为Wide Encoder,BiLSTM作为Contextual Encoder编码更长距离的上下文
- 先把两句话交互得到attention score矩阵,之后对于query中每个词,求得doc中最相似的词的分数,作为向量Max(S),按照同样的方法求出Mean(S),长度都为|Q|,再分别乘上query中每个词的tfidf统计,得到相关性匹配向量
- 用加性attention对query和doc进行交互,得到新的表示,再花式拼接过BiLSTM,得到语义匹配向量
- 将
拼接起来过MLP,最后分类
通过实验结果来看,Deep Encoder的表现是最好的,在7/8个评估上都超过另外两个。
模型只是工具,数据才是天花板,数据质不好/数量不够,模型再花哨也没用。像BiMPM和ESIM,小数据集无法发挥它们的效果,所以训练调参的过程会很耗时。像是quora question pairs数据集提供了40W对训练样本,不平衡程度也不大(正负比 3:5),这时两个模型效果都不错,这也印证了数据驱动的重要性。
小结
基于交互模型的方法实质就是在孪生网络架构的基础上, 通过某种策略对两个孪生网络的中间环节进行交互. 目前最普遍的策略是各种不同的Attention机制. 具有交互能力的模型结构普遍更为复杂, 包含更多的模型参数, 这就导致了这类模型的计算成本较高.
孪生 vs. 交互
- 基于表示的匹配方法优势在于Doc的语义向量可以离线预先计算,在线预测时只需要重新计算Query的语义向量速度会快很多;缺点是模型学习时Query和Doc两者没有任何交互,不能充分利用Query和Doc的细粒度匹配信号。
- 基于交互的匹配方法优势在于Query和Doc在模型训练时能够进行充分的交互匹配,语义匹配效果好,缺点是部署上线成本较高。
4.开源文本匹配工具
5.1 MatchZoo
MatchZoo 是一个Python环境下基于TensorFlow/keras开发的开源文本匹配工具,让大家更加直观地了解深度文本匹配模型的设计、更加便利地比较不同模型的性能差异、更加快捷地开发新型的深度匹配模型。
安装
1 | |
使用示例
1 | |
注意事项:
- 需要安装nltk中的词库(根据提示,缺啥装啥)
- 由于matchzoo的预处理模块是为英文设计的,需要进行中文适配,参考《matchzoo中文适配笔记》 《matchzoo中文支持研究笔记》
- 数据定义。需要将本地数据转换成
DataPack这种数据结构进行组织
1 | |
DataPack——>DataFrame:可以通过
df.frame()返回DataFrame类型进行查看;DataFrame——>DataPack:通过顶级函数
pack将DataFrame数据直接转换为DataPackDataPack——>
(X, y)元组:通过unpack函数进行拆包,其中X为{str: np.array}的键值对,拆包后的数据可直接用于模型的fit或fit_generator函数进行;y是二维列表,对应实际的标签值。
对上面的
DataPack类型进行转换为Dataset,定义这个类的时候,参数中有mode,可以选择point和pair这两种模式。pair模式下的采样过程:
以
id_left为标准进行分组,并按照label进行降序排序对于不同的组(group):
- 获取当前组的所有不同的
labels 对于除了最后一个之外的
labels(即labels[:-1]):- 获取等于当前
label的所有样本,重复num_dup的次数; - 将小于当前
label的所有样本作为负例; - 对于每一个正样本,采样
num_neg个负样本; - 按照
(pos_sample, neg_sample)的形式添加到pairs列表中。
- 获取等于当前
- 获取当前组的所有不同的
将所有的
pairs进行concat。
5.2 Deep text matching
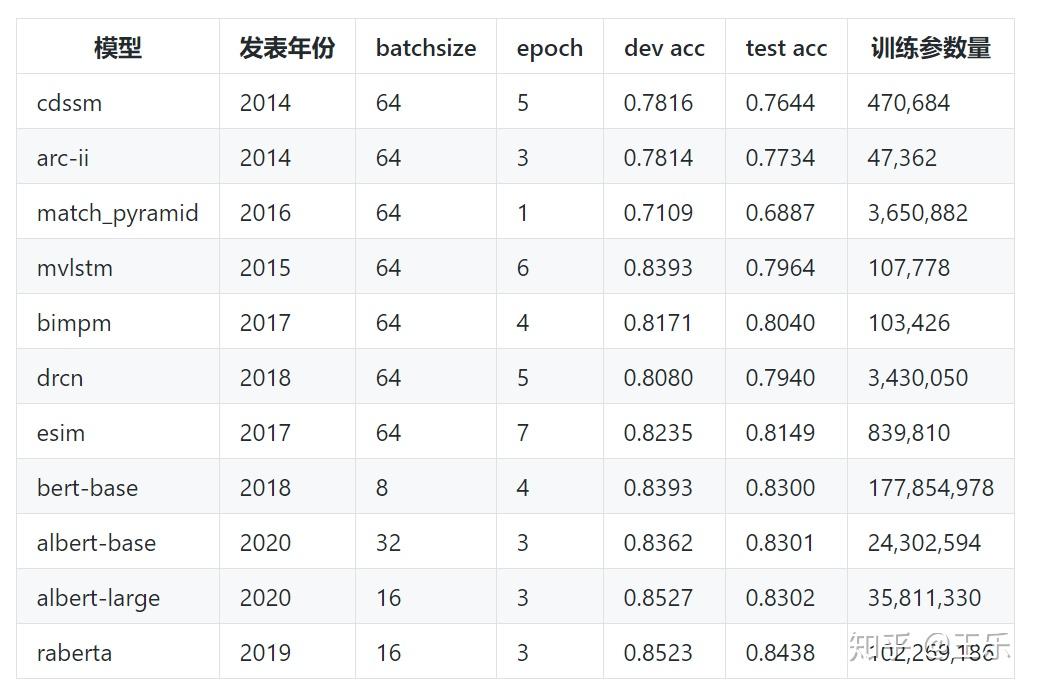
借鉴了 MatchZoo 和 text_matching ,使用 keras 深度学习框架进行复现cdssm, arc-ii,match_pyramid, mvlstm ,esim, drcn ,bimpm 等模型,借鉴了 bert4keras 项目的代码测试了几个 bert 系列模型(bert 及其变体)
5.3 shenweichen/DeepMatch
DeepMatch is a deep matching model library for recommendations & advertising. It’s easy to train models and to export representation vectors for user and item which can be used for ANN search.You can use any complex model with model.fit()and model.predict() .