Prompting, Instruction, RLHF
之前看了李宏毅老师的深度强化学习课程,内容从浅入深,娓娓道来,但是过了两天知识点全忘了(实际是记不住,也有点理解不到位)…..今天偶然间看到了斯坦福大学CS224N《深度学习自然语言处理》的 Prompting, Instruction Finetuning, and RLHF 这一讲的课件,读完之后顿觉醍醐灌顶,再加上课件本身逻辑清晰、内容层层推进且覆盖了NLP领域最新进展(2023年冬季课程),于是对此课件进行简要总结,以备后续不时之需。
具体分为了下面三节:
- Zero-Shot (ZS) and Few-Shot (FS) In-Context Learning
- Instruction finetuning——指令微调
- Reinforcement Learning from Human Feedback (RLHF)——人类反馈的强化学习
Zero-Shot (ZS) and Few-Shot (FS) In-Context Learning
这一节先从GPT模型的演进引入,首先表述了随着模型参数和训练数据的增大,语言模型逐步涌现(emerging)出了一些能力,这些从GPT对应的论文就可以看出端倪。
GPT-2对应的论文 Language Models are Unsupervised Multitask Learners,讲述了语言模型是无监督的多任务学习器,在论文中,进一步阐述了预训练好的GTP-2模型在没有进行微调和参数更新的的情况下,在8个零样本学习的任务中取得了7个任务的SOTA。这表明此时的GPT-2已经涌现出了零样本学习的能力。
GPT-3的论文 Language Models are Few-Shot Learners,讲述了语言模型是少样本学习器。在这篇论文里,作者们阐述了在简单的任务前添加少量样例的情况下(Specify a task by simply prepending examples of the task before your example),语言模型也能够SOTA的结果。这说明GPT-3已经涌现出了基于上下文的少样本学习能力。同时,添加到任务前的样例也可以看作是一种prompting。
但是,对于复杂的任务(数学运算、逻辑推理等等),简单的给出结果并不能使模型给出正确的结果。此时,需要将提示词更换一种形式,这就引出了思维链提示词(Chain of Thought prompting,以下简称CoT Prompting)。简单地说,就是将推导的过程添加到提示词中。如下图所示:

CoT Prompting 样例
同时,Chain of Thought Prompting这个能力也是随着模型尺度的增大而出现的。

CoT Prompting 随模型尺度变化曲线
同时,也有工作探索了Zero-shot CoT Prompting和few-shot CoT Prompting,进而发现了一片新大陆——prompting engineering。
Instruction Finetuning
之所以有这个工作,是因为大模型生成的结果,与人类的偏好还是有些偏差,或者说没有跟用户的意图对齐(not aligned with user intent)。

为了保持模型现有的zero-shot、few-shot、CoT能力,自然而然地想到可以在预训练好的大模型上进行微调(finetuing),只不过这时的微调与之前的微调有所区别。之前 Tuning是在某个下游任务 + 少量的 labels → 去微调/适配 PTM,而 Instruction是多任务的微调,在大量的任务指令+大量的 labels → 去适配不同的任务!
这里,我想花点时间介绍下Instruction Tuning和之前的Prompting、Fine Tuning。三者都是针对预训练模型进行微调的方法,它们的区别如下:
- Fine Tuning:在预训练模型的基础上,针对特定任务进行微调,比如针对猫狗分类任务进行微调。Fine Tuning需要有大量的任务相关数据,且可能会导致预训练的通用性能力下降。
- Prompting:在Fine Tuning之前,先给定一些文本片段作为Prompt,让模型在生成文本时遵循这些Prompt的要求,例如给定“请分类这张图片是否是猫”作为Prompt,让模型输出是或不是。这种方法可以让模型更好地遵循任务的要求,但是需要手动设计Prompt,且精调后的模型只能应用于特定的单一任务!
- Instruction Tuning:在Fine Tuning的基础上,通过给定一系列的任务指令,经过多任务精调后,能够在 unseen 任务上做zero-shot!。Instruction Tuning可以减少手动设计Prompt的工作量,同时也能够保持预训练模型的通用性能力。
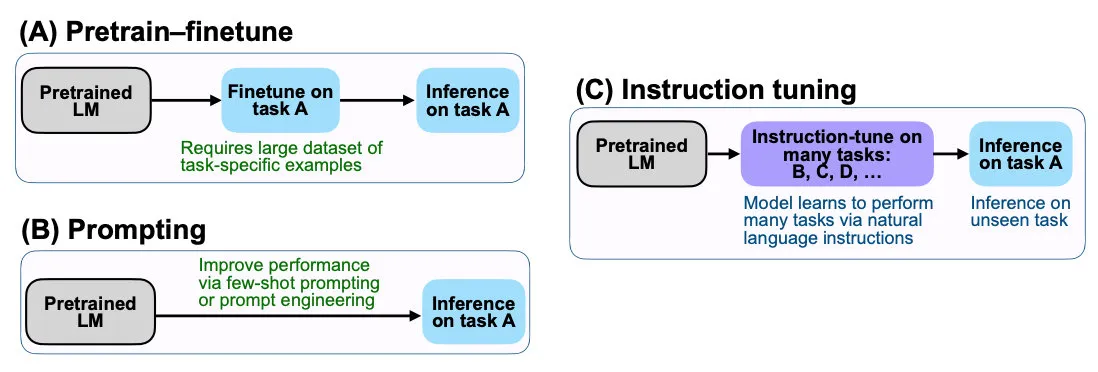
Instruction Tuning和Prompt的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,它的模版是这样的:

而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的action。比如NLI/分类任务:
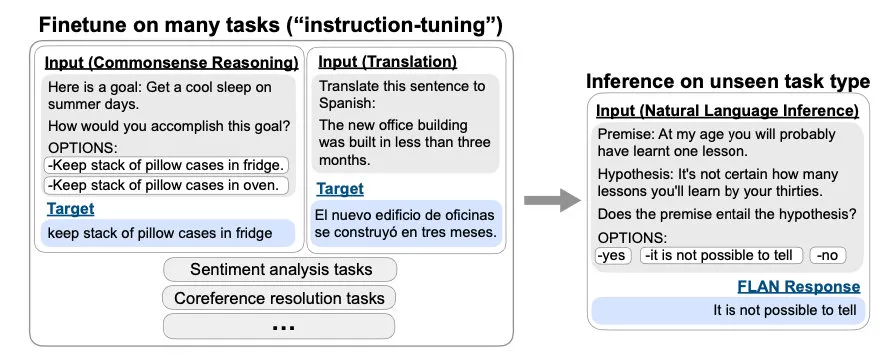
怎么做Instruction Tuning?
具体而言,就是将不同的任务 通过指令模版 抽象为(instruction, output)二元组,喂给模型,同时更新模型参数。

Instruction Finetuing
需要注意的是,这一步就有点像预训练了,需要很大的数据集和很大的模型。所以课件中戏称instruction finetuning为instruction pretraining,成了两阶段预训练。
instruction finetuing 的缺点有两个:

为了解决上述两个缺点,RLHF出场了,explicitly attempt to satisfy human preferences?
Reinforcement Learning from Human Feedback (RLHF)
强化学习基本知识可以参考王树森和张志华老师写的一本书——《深度强化学习》,这本书还有对应的视频教程,讲解深入浅出,值得一看。
图解人工反馈强化学习(RLHF) - Hugging Face
因为训练得到的模型并不是非常可控的,模型可以看做对训练集分布的一个拟合。那么反馈到生成模型中,训练数据的分布便是影响生成内容的质量最重要的一个因素。有时候我们希望模型并不仅仅只受训练数据的影响,而是人为可控的,从而保证生成数据的有用性,真实性和无害性。论文中多次提到了对齐(Alignment)问题,我们可以理解为模型的输出内容和人类喜欢的输出内容的对齐,人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
我们知道强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人工反馈的强化学习便应运而生。
RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
为了应用强化学习,需要构造出一个reward函数,该函数将语言模型生成的句子作为输入,输出句子对应的评分。比如在文本摘要任务,对于某个句子 𝑠,假设我们有一种方法可以获得 LM 输出摘要的人类奖励:$𝑅(𝑠) ∈ ℝ$,越高越好。训练的目标就是最大化 LM 的期望奖励:

那该如何做呢?最先想到的肯定是梯度下降,但是会存在两个问题:①如何估计这个期望?②$𝑅(𝑠)$奖励函数不可导怎么办?不用担心,强化学习中的策略梯度方法(Policy gradient)已经解决了这些问题!

策略梯度的关键思想是提高导致更高回报的行动的概率,并降低导致较低回报的行动的概率,直到你达到最优政策。简单的策略梯度介绍如下:


想了解详细的策略梯度以及 PPO 算法,可移步到《PPO笔记(转载-李宏毅DRL)》
Awesome:现在对于任意的、不可微分的奖励函数$𝑅(𝑠)$,我们都可以训练一个语言模型来最大化期望奖励。Not so fast! (Why not?) 。对于奖励函数$𝑅(𝑠)$的构造,还需要考虑如下的两个问题:
- 问题 1:人在整个回路中的成本很高!
解决方案:与其直接询问人类的偏好,不如将他们的偏好建模为一个单独的 (NLP) 问题!让 AI 训练 AI….采用一个神经网络来对奖励进行学习
问题 2:人类的判断是嘈杂和主观的!
- 解决方案:不要求奖励模型对句子直接评分,而是要求成对比较,这样训练更可靠

有了 reward 函数,以及大语言模型,再有一个依据reward对语言模型参数进行更新的策略,就可以进行RLHF了。具体如下图所示:

对仅预训练、Instruction Finetuning、RLHF的效果进行了对比,结果如下:
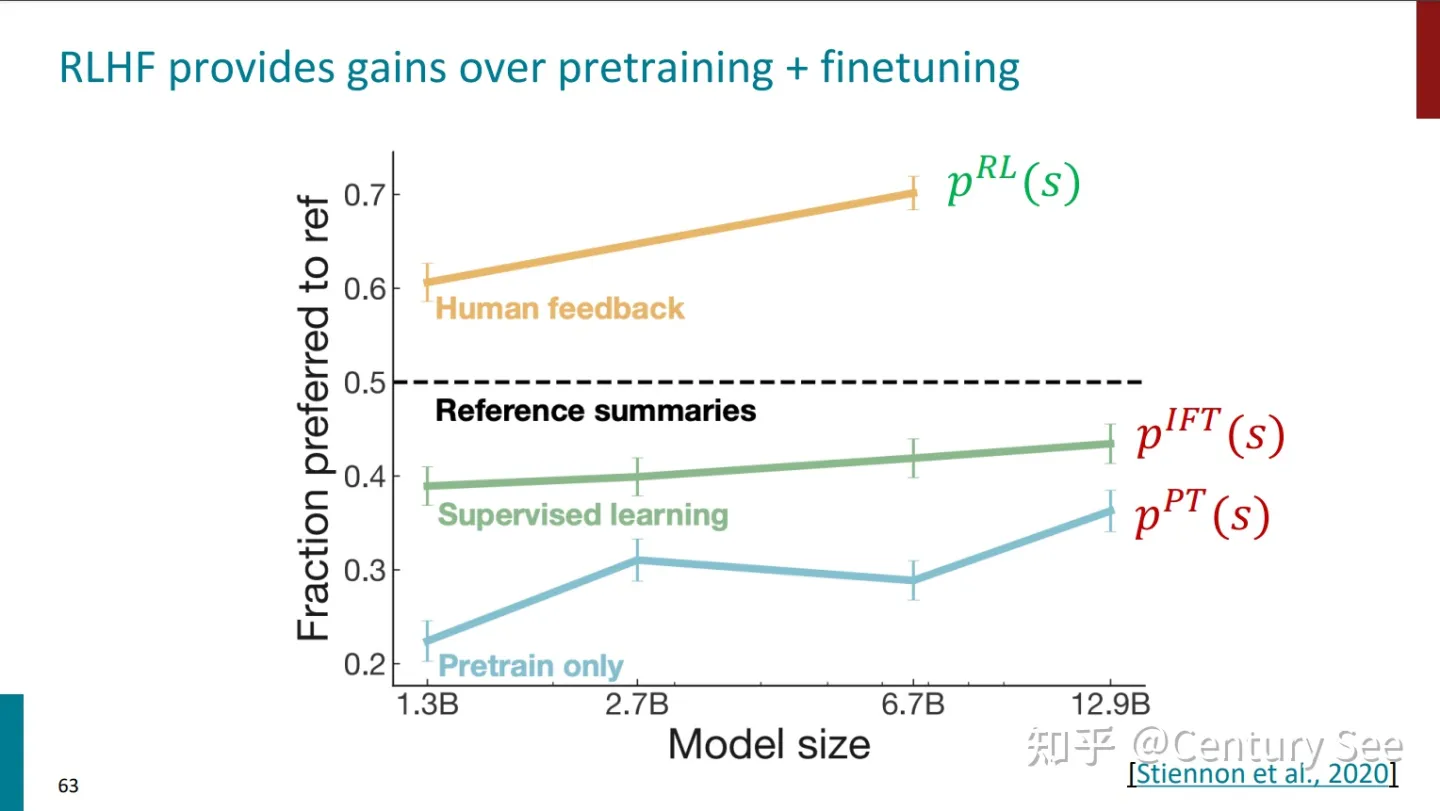
RLHF、Instruction Finetuning、仅预训练的效果对比
但是,最后还要说明一点,采用了RLHF方法的模型,虽然能够产生看上去更权威更有帮助的结果,但生成结果的真实性却值得商榷。(Chatbots are rewarded to produce responses that seem authoritative and helpful, regardless of truth)
这一节的内容就到这里,最后做个总结:
- InstructGPT: scaling up RLHF to tens of thousands of tasks
- ChatGPT: Instruction Finetuning + RLHF for dialog agents


从语言模型到AI助手