InstructGPT
Training language models to follow instructions with human feedback
赛尔笔记 | 浅析ChatGPT的原理及应用
InstructGPT要做什么?
InstructGPT 是 GPT3 的微调版本。GPT3 是受过文本补全训练的 LLM。你给它一些提示;它预测下一个对它有意义的词。但有个问题!由于它只进行文本补全,它并不能真正“理解”您的提示,而且对话更加不连贯。即使在试图用“及时的工程”来哄骗它之后,它也可能会产生错误的、有毒的或反映有害情绪的反应。换句话说,大模型产生的回复与人类真实的回复是有偏置的。InstructGPT的目标就是缓解这种生成回复与真实回复之间的偏置,产生更加符合人类预期的回复。
InstructGPT是怎么做的?
在这篇工作里,OpenAI的研究人员从数据层面和方法层面两方面对模型生成的质量进行了改善。数据层面,聘请标注人员标注一部分训练数据用于微调GPT3;而方法层面使用基于人工反馈的强化学习方法(RLHF)对模型进一步进行微调,使其生成结果更符合人类预期
数据层面,如下图所示,标注分为两个阶段(Instruction Tuning):①标注一些任务相关的Prompt(描述了要进行的任务),然后②从Prompt中采样一部分,标注人员写出其理想的回复。之后,这些人工构造出来的高质量数据demonstration(prompt-responsee)被用作微调GPT3之中。
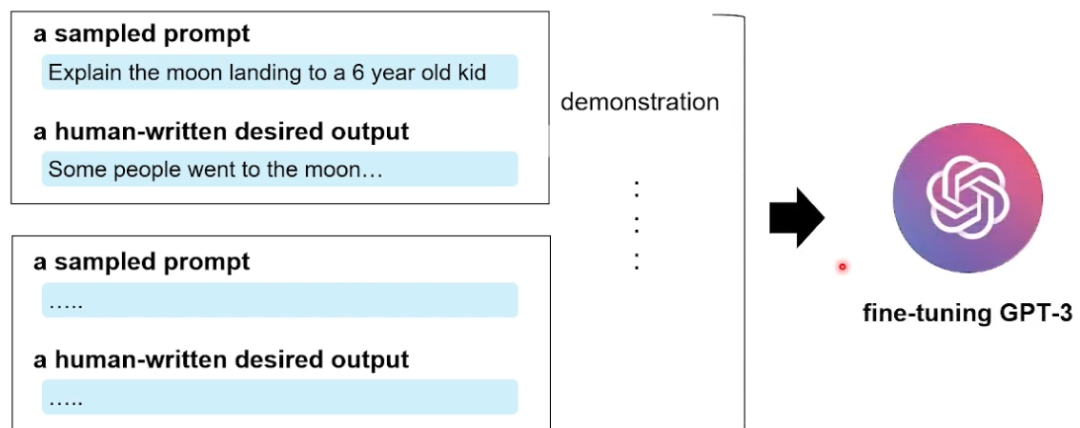
图6 InstructGPT 数据标注示意图[2]
方法层面,如下图所示,InstructGPT的训练实际上是分为三个阶段的(RLHF),第一阶段就是我们上文所述,利用人工标注的prompt-response数据微调GPT3;第二阶段,需要训练一个评价模型即Reward Model,该模型需学习人类对于模型回复的评价方式,对于输出的prompt-response pair人工进行打分排序;第三阶段,利用训练好的Reward Model作为反馈信号,去指导GPT进一步进行微调,将目标设定为Reward分数最大化,从而使模型产生更加符合人类偏好的回复(PPO)。
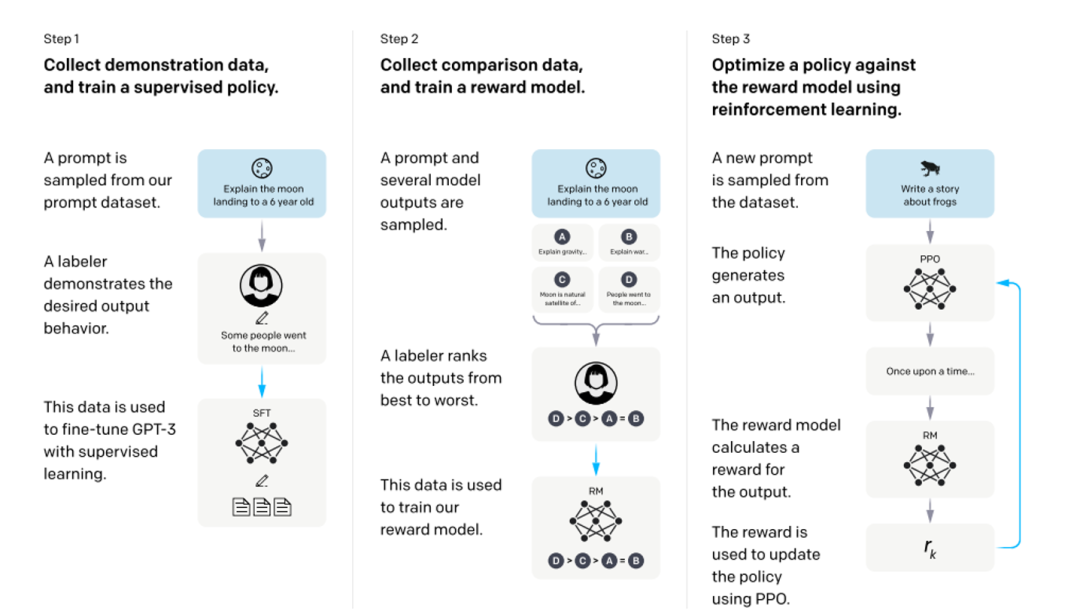
图7 InstructGPT整体训练流程[3]
如何训练一个Reward Model

那么该工作是如何训练的Reward Model呢?评价模型实际上是利用大模型做一个回归任务,相信回归任务大家应该都比较熟悉,即在模型的输出层[CLS]位置添加一个MLP,最后得到的数值即为Reward Model给出的分数。
接下来我们看一下OpenAI是如何构造数据的,如下图所示,在训练Reward Model的时候采用排序任务,即针对同一个上文,利用第一阶段训练好GPT3在多次采样下可以生成4个( 或9个)不同的回复。标注人员在标注过程中,需要根据这4个不同回复与上文之间的关联程度,给出一个相关性的偏序关系。
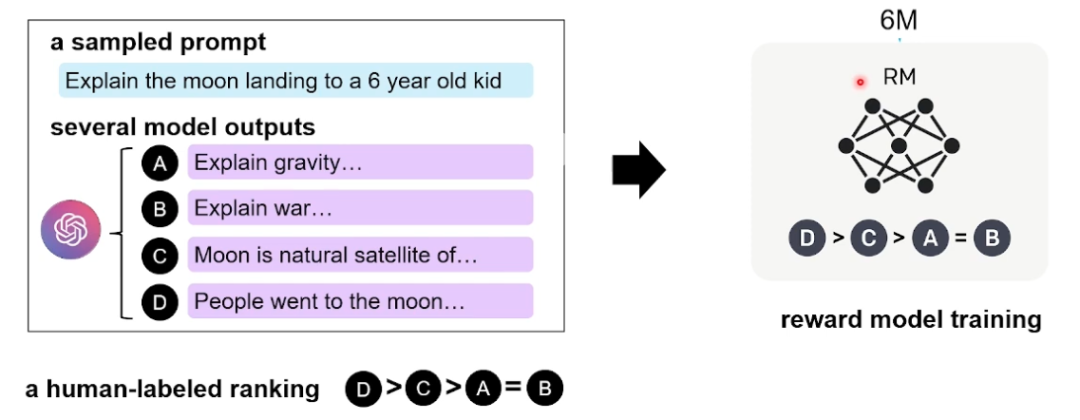
图8 InstructGPT第二阶段的数据标注过程与训练过程[2]
在训练阶段,这4个回复之间两两组合可以形成$C_4^2=6$个pair,优化目标为每对之中与上文关系大的分数高于与上文关系小的,Reward Model 损失函数为 pairwise loss:
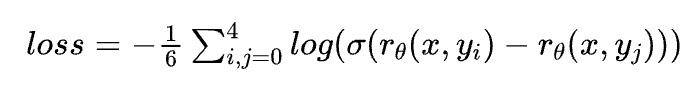
其中$r_θ(x,y)$是奖励值,$y_i$是排名相对靠前的结果,$y_j$是排名相对靠后的结果。这个损失函数的目标是最大化好的回复结果和不好的回复结果之间的差值。
归纳下:在这个阶段里,首先由冷启动后的监督策略模型 SFT 为每个prompt产生K个结果,人工根据结果质量由高到低排序,以此作为训练数据,通过pair-wise learning to rank模式来训练回报模型。对于学好的RM模型来说,输入
基于人工反馈的微调 RLHF
在第二阶段训练好一个Reward Model以后,我们就可以利用这个模型作为反馈信号,代替人类去指导大模型进行微调了。在该阶段OpenAI采用近端策略优化算法(PPO)这一强化学习方法对模型进行微调,可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。
PPO算法是OpenAI之前提出的一个针对策略梯度算法进行改进的算法。这一算法目前已经广泛应用于各种强化学习模型中,并被证实有良好的性能。但是,将这一算法应用于序列生成任务中的相关工作却少之又少。
PPO 算法的详细介绍请移步 PPO:Proximal Policy Optimization
模型整体流程如下图所示,其中Policy Model就是第三阶段进行微调的GPT3, Alignment Model是固定参数不参与微调的GPT3,两者均由阶段一训练的GPT3进行初始化;Value Function Model是一个可训练的价值函数,其输出值代表着GPT3生成的每一个token的质量,是一个短期的奖励, Reward Model是一个固定参数的模型,其输出值代表着整个句子的好坏程度,是一个长期奖励。
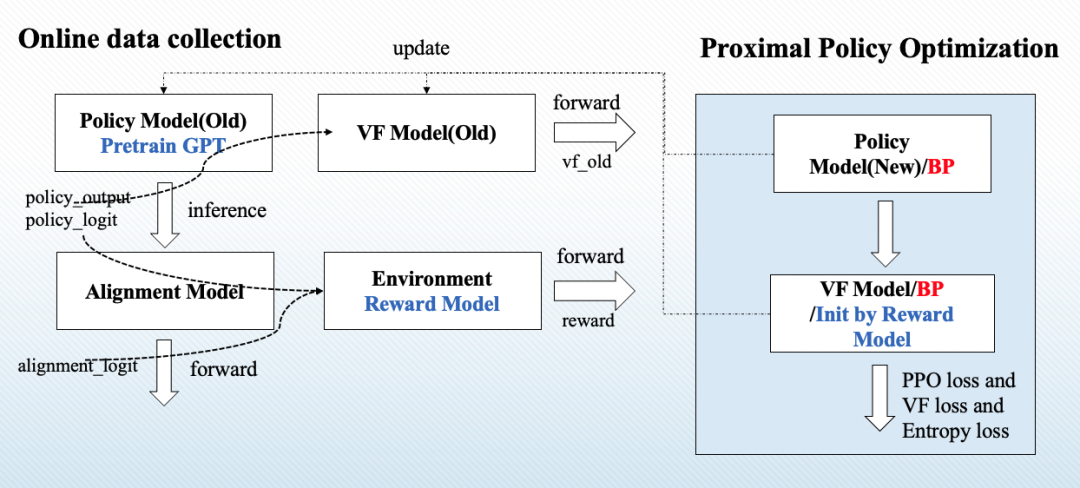
图9 InstructGPT第三阶段训练流程示意图
首先,对于一个给定的对话上文,通过Policy Model可以得到关于每一步生成的词表上的概率分布;与此同时通过Alignment Model可以得到一个未经过三阶段微调的模型给出的词表上的概率分布。将两者传入Reward Model, 评价模型会根据生成质量给出一个分数,并计算Policy Model与 Alignment Model之间的差异性,将这个分数作为一个额外的惩罚项,若Policy Model生成结果过于天马行空,导致与未经过训练前的模型相距甚远,则会因为过高的惩罚被赋予低分。
这个计算结果即为Reward。同时,将policy model的输出传递给 value function model,其将计算出生成序列中每一个token的分数,即为价值函数分数。重复以上步骤直到收集完成一个mini-batch的所有数据,则在线数据收集完成。
实验结果
OpenAI采用人工评测,让标注者从真实性(truthful)、毒害性(toxic)、事实性(make up fact)和合理性(appropriate)四个角度对InstructGPT与GPT3进行评价。标注人员会在不知情的条件下,拿到GPT3和InstructGPT生成的回复,其需要比较两者之间的好坏关系。如下图所示,1.3B 参数的 InstructGPT 模型的输出人们略偏好于 175B GPT-3,而同等参数下的InstructGPT更是有超过六成的胜率。
图11 InstructGPT与GPT3的胜率对比,其中PPO即为InstructGPT,GPT代表GPT3[3]
InstructGPT小结
InstructGPT为解决大模型生成回复不符合人们预期这一问题,分别从数据和模型两方面进行了设计,通过改善数据质量与基于人工反馈的微调两个方面减小了模型生成回复与人类真实回复之间的偏置。并且在实验中表明,在GPT3 1/100 的参数条件下表现出相近的性能。