LangChain 实战
参考官方文档、LangChain 的中文入门教程、LangChain CheatSheet、gkamradt/langchain-tutorials
介绍
众所周知 OpenAI 的 API 无法联网的,所以如果只使用自己的功能实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频进行问答等等的功能肯定是无法实现的。所以,我们来介绍一个非常强大的第三方开源库:LangChain 。
LangChain 是由Harrison Chase创建的一个 Python 库,可帮助您在几分钟内构建 GPT 驱动的应用程序。他主要拥有 2 个能力:
- 可以将 LLM 模型与外部数据源进行连接
- 允许与 LLM 模型进行交互
您可以使用 LangChain 构建的有趣应用程序包括(但不限于):
- 聊天机器人
- 特定领域的总结和问答
- 查询数据库以获取信息然后处理它们的应用程序
- 解决特定问题的代理,例如数学和推理难题
在本指南中,我们将探讨什么是 LangChain 以及您可以使用它构建什么。我们还将尝试使用 LangChain 构建一个简单的问答应用程序。
LangChain 模块概述
接下来我们看一下LangChain中的一些模块:

Models
LangChain 为许多不同的 LLM 提供了通用接口,可以直接通过 API 工作,但也可以运行本地模型。
- 大型语言模型 LLM:将文本字符串作为输入,并返回文本字符串作为输出
- Chat Models:将聊天消息列表作为输入,并返回聊天消息。
- Text Embedding Models:将文本作为输入并返回一个浮点数组成的向量
LLMs
LLMs 是 LangChain 的基础组成部分。它本质上是一个大型语言模型的包装器,可以通过该接口与各种大模型进行交互。LLMs 类的功能如下:
- 支持多种模型接口,如 OpenAI、Hugging Face Hub、Anthropic、Azure OpenAI、GPT4All、Llama-cpp…
- Fake LLM,用于测试
- 缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
用量记录
支持流模式(就是一个字一个字的返回,类似打字效果)
langchain.llms 使用示例
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003", n=2, best_of=2)
llm("Tell me a joke")
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"])
llm_result.llm_output # 返回 tokens 使用量How to cache LLM calls
from langchain.llms import OpenAI
import langchain
from langchain.cache import InMemoryCache,SQLiteCache,RedisCache
langchain.llm_cache = InMemoryCache()
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
llm("Tell me a joke") # time: 1.1 s
llm("Tell me a joke") # time: 175 µs
from redis import Redis
from langchain.cache import RedisCache
langchain.llm_cache = RedisCache(redis_=Redis())
llm("Tell me a joke") # time: 825 ms
llm("Tell me a joke") # time: 2.67 ms
# 基于语义相似性缓存结果
import gptcache
from gptcache.processor.pre import get_prompt
from gptcache.manager.factory import get_data_manager
from langchain.cache import GPTCache
from gptcache.manager import get_data_manager, CacheBase, VectorBase
from gptcache import Cache
from gptcache.embedding import Onnx
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
# Avoid multiple caches using the same file, causing different llm model caches to affect each other
i = 0
file_prefix = "data_map"
llm_cache = Cache()
def init_gptcache_map(cache_obj: gptcache.Cache):
global i
cache_path = f'{file_prefix}_{i}.txt'
onnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase('faiss', dimension=onnx.dimension)
data_manager = get_data_manager(cache_base, vector_base, max_size=10, clean_size=2)
cache_obj.init(
pre_embedding_func=get_prompt,
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
i += 1
langchain.llm_cache = GPTCache(init_gptcache_map)
llm("Tell me a joke") # time: 2.49 s
llm("Tell me a joke") # time: 136 ms
# This is not an exact match, but semantically within distance so it hits!
llm("Tell me joke") # time: 135 ms在磁盘上写入和读取 LLM 配置
llm.save("llm.json")
llm = load_llm("llm.json")
# {
# "model_name": "text-davinci-003",
# "temperature": 0.7,
# "max_tokens": 256,
# "top_p": 1.0,
# "frequency_penalty": 0.0,
# "presence_penalty": 0.0,
# "n": 1,
# "best_of": 1,
# "request_timeout": null,
# "_type": "openai"
# }如何流式传输 LLM 和聊天模型响应
from langchain.llms import OpenAI, Anthropic
from langchain.chat_models import ChatOpenAI
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.schema import HumanMessage
llm = OpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0)
resp = llm("请给我解释 Langchain 是什么")
chat = ChatOpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0)
resp = chat([HumanMessage(content="请给我解释 Langchain 是什么")])
# Anthropic的claude模型
llm = Anthropic(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0)
llm("Write me a song about sparkling water.")Chat Models
langchain.chat_models 使用示例
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(temperature=0)
chat([HumanMessage(content="Translate this sentence from English to Chinese. I love programming.")])
# 支持多条消息作为输入
batch_messages = [
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="Translate this sentence from English to French. I love programming.")
],
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="Translate this sentence from English to French. I love artificial intelligence.")
],
]
result = chat.generate(batch_messages)
print(result)
print(result.llm_output)LLM Chain 使用示例
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
llm = ChatOpenAI(temperature=0)
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step."""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
example_human = HumanMessagePromptTemplate.from_template("Hi")
example_ai = AIMessagePromptTemplate.from_template("Argh me mateys")
human_message_prompt = HumanMessagePromptTemplate.from_template("{text}")
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, example_human, example_ai, human_message_prompt])
chat_prompt.format_prompt(context=context, question="")
chain = LLMChain(llm=llm, prompt=chat_prompt)
chain.run()如何流式传输
from langchain.chat_models import ChatOpenAI from langchain.schema import HumanMessage from langchain.callbacks.base import CallbackManager from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler chat = ChatOpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0) resp = chat([HumanMessage(content="请给我解释 Langchain 是什么")])
HuggingFace Models
使用 HuggingFace 模型之前,需要先设置环境变量
1 | |
将模型拉到本地使用的好处:
- 训练模型
- 可以使用本地的 GPU
- 有些模型无法在 HuggingFace 运行
Text Embedding Models
LangChain 中的基础 Embedding 类是设计用于与嵌入交互的类,它提供了两个方法:embed_documents和embed_query。最大的区别在于这两种方法具有不同的接口:一种处理多个文档,而另一种处理单个文档。
Embedding 类能够帮助我们实现基于知识库的问答和semantic search,相比 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
文本嵌入模型集成了如下的源:AzureOpenAI、Hugging Face Hub、InstructEmbeddings、Llama-cpp、OpenAI 等
1 | |
1 | |
1 | |
Prompts
“提示”是指模型的输入。PromptTemplate 负责构建此输入,LangChain 提供了可用于格式化输入和许多其他实用程序的提示模板。
- LLM Prompt Templates
- Chat Prompt Templates
- Example Selectors
- Output Parsers
1 | |
Indexes
索引指的是构建文档的方式,以便 LLM 可以最好地与它们交互。Indexes主要有 4 个主要组件:
- 文档加载器:如何从各种来源加载文档
- 文本拆分器:拆分文本成多个chunk
- VectorStores:对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand。默认情况下,LangChain 使用Chroma作为向量存储来索引和搜索嵌入
- 检索器:
快速入门
此示例展示了对文档的问答。文档问答包括四个步骤:
- 创建索引
- 从该索引创建一个检索器
- 创建问答链
- 问问题!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# pip install chromadb
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 指定要使用的文档加载器
from langchain.document_loaders import TextLoader
documents = TextLoader('../state_of_the_union.txt', encoding='utf8')
# 接下来,我们将文档拆分成块。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 然后我们将选择我们想要使用的嵌入。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# 我们现在创建 vectorstore 用作索引。
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# 这就是创建索引。然后,我们在检索器接口中公开该索引。
retriever = db.as_retriever()
# 创建一个链并用它来回答问题!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
Document Loaders and Utils
LangChain 的Document Loaders和Utils模块分别用于连接到数据源和计算源。
当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
假设你有大量的经济学文本语料库,你想在其上构建 NLP 应用程序。您的语料库可能是文本文件、PDF 文档、HTML 网页、图像等的混合体。那么,通过 Document Loaders 的Unstructured 可以将这些原始数据源转换为可处理的文本。
The following document loaders are provided:
- CSV Loader CSV文件
- DataFrame Loader 从 pandas 数据帧加载数据
- Diffbot 从 URL 列表中提取 HTML 文档,并将其转换为我们可以在下游使用的文档格式
- Directory Loader 加载目录中的所有文档
- EverNote 印象笔记
- Git 从 Git 存储库加载文本文件
- Google Drive Google网盘
- HTML HTML 文档
- Markdown
- Notebook 将 .ipynb 笔记本中的数据加载为适合 LangChain 的格式
- Notion
- PowerPoint
- Unstructured File Loader 使用Unstructured加载多种类型的文件,目前支持加载文本文件、powerpoints、html、pdf、图像等
- URL 加载 URL 列表中的 HTML 文档内容
- Word Documents
更多的加载器可以看看链接。
Text Spltters
顾名思义,文本分割就是用来分割文本的。为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 embedding 功能都是有字符限制的。
比如我们将一份300页的 pdf 发给 openai api,让他进行总结,他肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
- 默认推荐的文本拆分器是 RecursiveCharacterTextSplitter。默认情况以 [“\n\n”, “\n”, “ “, “”] 字符进行拆分。其它参数说明:
length_function如何计算块的长度。默认只计算字符数,但在这里传递令牌计数器是很常见的。chunk_size:块的最大大小(由长度函数测量)。chunk_overlap:块之间的最大重叠。有一些重叠可以很好地保持块之间的一些连续性(例如,做一个滑动窗口) - CharacterTextSplitter 默认情况下以
separator="\n\n"进行拆分 - TiktokenText Splitter 使用OpenAI 的开源分词器包来估计使用的令牌
1 | |
1 | |
Vectorstores
因为数据相关性搜索其实是向量运算。所以,不管我们是使用 openai api embedding 功能还是直接通过 向量数据库 直接查询,都需要将我们加载进来的数据 Document 进行向量化,才能进行向量运算搜索。转换成向量也很简单,只需要我们把数据存储到对应的向量数据库中即可完成向量的转换。
官方也提供了很多的向量数据库供我们使用,包括:
更多支持的向量数据库使用方法,可转至链接。
1 | |
1 | |
1 | |
1 | |
1 | |
Retrievers
检索器接口是一个通用接口,可以轻松地将文档与语言模型结合起来。此接口公开了一个 get_relevant_documents 方法,该方法接受一个查询(一个字符串)并返回一个文档列表。
一般来说,用的都是 VectorStore Retriever。顾名思义,此检索器由 VectorStore 大力支持。一旦你构造了一个 VectorStore,构造一个检索器就很容易了。
1 | |
Chains
Chain 可以根据特定任务将 LLM 调用链接在一起。例如,您可能需要从特定 URL 获取数据,总结返回的文本,并使用生成的摘要回答问题。链允许我们将多个组件组合在一起以创建一个单一的、连贯的应用程序。例如,我们可以创建一个接受用户输入的链,使用 PromptTemplate 对其进行格式化,然后将格式化后的响应传递给 LLM。我们可以通过将多个链组合在一起,或者通过将链与其他组件组合来构建更复杂的链。
- LLMChain
- 各种工具Chain
- LangChainHub
快速入门
LLMChain是一个简单的链,它接受一个提示模板,用用户输入格式化它并返回来自 LLM 的响应。在多步骤工作流程中结合 LLM 和提示。1
2
3
4
5
6
7from langchain import LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "Can Barack Obama have a conversation with George Washington?"
print(llm_chain.run(question))1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37from langchain.llms import OpenAI
from langchain.docstore.document import Document
import requests
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
import pathlib
import subprocess
import tempfile
"""
生成对以前撰写的博客文章有理解的博客文章,或者可以参考产品文档的产品教程
"""
source_chunks = ""
search_index = Chroma.from_documents(source_chunks, OpenAIEmbeddings())
from langchain.chains import LLMChain
prompt_template = """Use the context below to write a 400 word blog post about the topic below:
Context: {context}
Topic: {topic}
Blog post:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "topic"]
)
llm = OpenAI(temperature=0)
chain = LLMChain(llm=llm, prompt=PROMPT)
def generate_blog_post(topic):
docs = search_index.similarity_search(topic, k=4)
inputs = [{"context": doc.page_content, "topic": topic} for doc in docs]
print(chain.apply(inputs))
generate_blog_post("environment variables")
执行多个chain
顺序链是按预定义顺序执行其链接的链。具体来说,我们使用SimpleSequentialChain,其中每个步骤都有一个输入/输出,一个步骤的输出是下一个步骤的输入。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
# location 链
llm = OpenAI(temperature=1)
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
location_chain = LLMChain(llm=llm, prompt=prompt_template)
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
meal_chain = LLMChain(llm=llm, prompt=prompt_template)
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("Rome")
load_qa_chain
Load question answering chain.1
2
3
4
5
6
7def load_qa_chain(
llm: BaseLanguageModel,
chain_type: str = "stuff",
verbose: Optional[bool] = None,
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> BaseCombineDocumentsChain:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.prompts import PromptTemplate
from langchain.indexes.vectorstore import VectorstoreIndexCreator
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))]).as_retriever()
# retriever=docsearch.as_retriever()
query = "What did the president say about Justice Breyer"
docs = docsearch.get_relevant_documents(query)
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
query = "What did the president say about Justice Breyer"
chain.run(input_documents=docs, question=query)
RetrievalQA
Chain for question-answering against an index.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39"""
此示例展示了对文档的问答。文档问答包括四个步骤:
1. 创建索引
2. 从该索引创建一个检索器
3. 创建问答链
4. 问问题!
"""
# pip install chromadb
from langchain.chains import RetrievalQA
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
from langchain.document_loaders import DirectoryLoader
# 加载文件夹中的所有txt类型的文件,并转成 document 对象
loader = DirectoryLoader('./data/', glob='**/*.txt')
documents = loader.load()
# 接下来,我们将文档拆分成块。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 然后我们将选择我们想要使用的嵌入。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# 我们现在创建 vectorstore 用作索引,并进行持久化
from langchain.vectorstores import Chroma
# vector_store = Chroma.from_documents(texts, embeddings, persist_directory="./vector_store")
# vector_store.persist()
vector_store = Chroma(persist_directory="./vector_store", embedding_function=embeddings)
# 这就是创建索引。然后,我们在检索器接口中公开该索引。
retriever = vector_store.as_retriever()
# 创建一个链并用它来回答问题!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
print(qa.input_keys, qa.output_keys)
query = "出差申请单修改"
print(qa.run(query=query))
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=OpenAI(temperature=0), chain_type="stuff", retriever=retriever)
print(chain.input_keys, chain.output_keys)
print(chain({"question": "出差申请单修改"}, return_only_outputs=True))
VectorDBQA
Chain for question-answering against a vector database.1
2
3
4
5vector_store = Chroma.from_documents(split_docs, embeddings)
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=vector_store,return_source_documents=True)
# 进行问答
res = qa({"query": "未入职同事可以出差吗"})
print(res)
LLMRequestsChain
使用请求库从 URL 获取 HTML 结果,然后使用 LLM 解析结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23from langchain.llms import OpenAI
from langchain.chains import LLMRequestsChain, LLMChain
from langchain.prompts import PromptTemplate
template = """Between >>> and <<< are the raw search result text from google.
Extract the answer to the question '{query}' or say "not found" if the information is not contained.
Use the format
Extracted:<answer or "not found">
>>> {requests_result} <<<
Extracted:"""
PROMPT = PromptTemplate(
input_variables=["query", "requests_result"],
template=template,
)
chain = LLMRequestsChain(llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=PROMPT))
question = "What are the Three (3) biggest countries, and their respective sizes?"
inputs = {
"query": question,
"url": "https://www.google.com/search?q=" + question.replace(" ", "+")
}
chain(inputs)
SQLDatabaseChain
如何使用SQLDatabaseChain来回答数据库中的问题。
在底层,LangChain 使用 SQLAlchemy 连接到 SQL 数据库。因此,SQLDatabaseChain可以与 SQLAlchemy 支持的任何 SQL 方言一起使用,例如 MS SQL、MySQL、MariaDB、PostgreSQL、Oracle SQL 和 SQLite。有关连接到数据库的要求的更多信息,请参阅 SQLAlchemy 文档。例如,与 MySQL 的连接需要适当的连接器,例如 PyMySQL。MySQL 连接的 URI 可能类似于:
mysql+pymysql://user:pass@some_mysql_db_address/db_name
1 | |
注意:对于数据敏感的项目,可以return_direct=True在SQLDatabaseChain初始化时指定直接返回SQL查询的输出,不做任何额外的格式化。这可以防止 LLM 查看数据库中的任何内容。但是请注意,默认情况下,LLM 仍然可以访问数据库方案(即方言、表和键名)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32from langchain import OpenAI, SQLDatabaseChain
llm = OpenAI(temperature=0)
db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
db_chain.run("获取 flow=LXHITDH 且跟发票相关的知识")
# 自定义提示
from langchain.prompts.prompt import PromptTemplate
_DEFAULT_TEMP = """Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Use the following format:
Question: "Question here"
SQLQuery: "SQL Query to run"
SQLResult: "Result of the SQLQuery"
Answer: "Final answer here"
Only use the following tables:
{table_info}
If someone asks for the table foobar, they really mean the employee table.
Question: {input}"""
PROMPT = PromptTemplate(
input_variables=["input", "table_info", "dialect"], template=_DEFAULT_TEMP)
# 返回中间步骤
# top_k 返回最大结果数,相当于 limit
db_chain = SQLDatabaseChain(llm=llm, database=db, prompt=PROMPT, verbose=True, return_intermediate_steps=True, top_k=3)
result = db_chain("获取跟发票相关的知识")
result["intermediate_steps"]
Agents
我们提到“链”可以帮助将一系列 LLM 调用链接在一起。然而,在某些任务中,调用顺序通常是不确定的。下一步可能取决于用户输入和前面步骤中的响应。
对于此类应用程序,LangChain 库提供了代理“Agents”,它们可以根据未知的输入而不是硬编码来决定下一步采取的行动。 执行过程可以参考下面这张图:

agent 使用LLM来确定要采取哪些行动以及按什么顺序采取的行动。操作可以使用工具并观察其输出,也可以返回用户。创建agent时的参数:
- 工具:执行特定职责的功能。比如:Google搜索,数据库查找,Python Repl。工具的接口当前是一个函数,将字符串作为输入,字符串作为输出。
- LLM:为代理提供动力的语言模型。
- 代理:highest level API、custom agent
快速入门
代理使用 LLM 来确定采取哪些行动以及采取何种顺序。动作可以是使用工具并观察其输出,也可以是返回给用户。为了加载代理,您应该了解以下概念:
- 工具:执行特定任务的功能。这可以是:Google 搜索、数据库查找、Python REPL、其他链。工具的接口目前是一个函数,期望将字符串作为输入,将字符串作为输出。
- LLM:为代理提供支持的语言模型。
- 代理:要使用的代理。这应该是一个引用支持代理类的字符串。由于本笔记本侧重于最简单、最高级别的 API,因此仅涵盖使用标准支持的代理。如果您想实施自定义代理,请参阅自定义代理的文档(即将推出)。
1 | |
1 | |
1 | |
Tools
工具是代理可以用来与世界交互的功能。这些工具可以是通用实用程序(例如搜索)、其他链,比如:
- Bash 在终端中执行命令。输入应该是有效的命令,输出将是运行该命令的任何输出。
- Apify 一个用于网络抓取和数据提取的云平台
- Bing Search
- Google Search
- Human as a tool 人类是 AGI,当 AI 代理感到困惑时会进行询问
- LLM-MATH 对于您需要回答数学问题时有用。
- Open-Meteo-Api 对于您想从OpenMeteo API获取天气信息时很有用。
- Python REPL 使用它来执行 python 命令。输入应该是有效的 python 命令
- Requests 当您需要从站点获取特定内容时使用它。输入应该是一个特定的 url,输出将是该页面上的所有文本。
- SerpAPI 一个搜索引擎。当您需要回答有关时事的问题时很有用。输入应该是搜索查询。
- Wikipedia API
- Wolfram Alpha 当您需要回答有关数学、科学、技术、文化、社会和日常生活的问题时很有用。输入应该是搜索查询。
- Zapier Natural Language Actions API 可以通过自然语言 API 接口访问 Zapier 平台上的 5k+ 应用程序和 20k+ 操作
1 | |
1 | |
1 | |
1 | |
Custom Agent
- Custom Agent
- Custom LLM Agent
- Custom LLM Agent (with a ChatModel)
- Custom MRKL Agent
- Custom MultiAction Agent
- Custom Agent with Tool Retrieval
We also have documentation for an in-depth dive into each agent type.
Toolkits
带有工具包的代理1
2
3
4from langchain.agents import create_csv_agent
from langchain.llms import OpenAI
agent = create_csv_agent(OpenAI(temperature=0), 'titanic.csv', verbose=True)
agent.run("how many rows are there?")1
2
3
4
5
6
7
8
9
10
11
12
13from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True
)
agent_executor.run("What is the 10th fibonacci number?")
agent_executor.run("""Understand, write a single neuron neural network in PyTorch.
Take synthetic data for y=2x. Train for 1000 epochs and print every 100 epochs.
Return prediction for x = 5""")1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
db = SQLDatabase.from_uri("sqlite:///../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db)
# pip install langchain==0.0.136
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("Describe the playlisttrack table")1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI, VectorDBQA
llm = OpenAI(temperature=0)
from langchain.document_loaders import TextLoader
loader = TextLoader('../../../state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
state_of_union_store = Chroma.from_documents(texts, embeddings, collection_name="state-of-union")
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://beta.ruff.rs/docs/faq/")
docs = loader.load()
ruff_texts = text_splitter.split_documents(docs)
ruff_store = Chroma.from_documents(ruff_texts, embeddings, collection_name="ruff")
from langchain.agents.agent_toolkits import (
create_vectorstore_agent,
VectorStoreToolkit,
VectorStoreInfo,
)
vectorstore_info = VectorStoreInfo(
name="state_of_union_address",
description="the most recent state of the Union adress",
vectorstore=state_of_union_store
)
toolkit = VectorStoreToolkit(vectorstore_info=vectorstore_info)
agent_executor = create_vectorstore_agent(
llm=llm,
toolkit=toolkit,
verbose=True
)
agent_executor.run("What did biden say about ketanji brown jackson is the state of the union address?")
实战
1、完成一次简单问答
1 | |
2、构建本地知识库问答机器人(QA)
1 | |

3、Question Answering over Docs
对您的文档数据进行问答,可以使用: load_qa_chain, RetrievalQA, VectorstoreIndexCreator, ConversationalRetrievalChain
- Question Answering Notebook: A notebook walking through how to accomplish this task.
- VectorDB Question Answering Notebook: A notebook walking through how to do question answering over a vector database.
4、使用GPT3.5模型构建油管频道问答机器人
在 chatgpt api(也就是 GPT-3.5-Turbo)模型出来后,因钱少活好深受大家喜爱,所以 LangChain 也加入了专属的链和模型,我们来跟着这个例子看下如何使用他。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65import os
from langchain.document_loaders import YoutubeLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import ChatVectorDBChain, ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader.from_youtube_channel('https://www.youtube.com/watch?v=Dj60HHy-Kqk')
# 将数据转成 document
documents = loader.load()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=20
)
# 分割 youtube documents
documents = text_splitter.split_documents(documents)
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings()
# 将数据存入向量存储
vector_store = Chroma.from_documents(documents, embeddings)
# 通过向量存储初始化检索器
retriever = vector_store.as_retriever()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{context}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template('{question}')
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate.from_messages(messages)
# 初始化问答链
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.1,max_tokens=2048),retriever,qa_prompt=prompt)
chat_history = []
while True:
question = input('问题:')
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa({'question': question, 'chat_history': chat_history})
chat_history.append((question, result['answer']))
print(result['answer'])
5、langchain + zapier
我们主要是结合使用 zapier 来实现将万种工具连接起来。
所以我们第一步依旧是需要申请账号和他的自然语言 api key。
https://zapier.com/l/natural-language-actions
他的 api key 虽然需要填写信息申请。但是基本填入信息后,基本可以秒在邮箱里看到审核通过的邮件。然后,我们通过右键里面的连接打开我们的api 配置页面。我们点击右侧的 Manage Actions 来配置我们要使用哪些应用。
api 配置
我在这里配置了 Gmail 读取和发邮件的 action,并且所有字段都选的是通过 AI 猜。
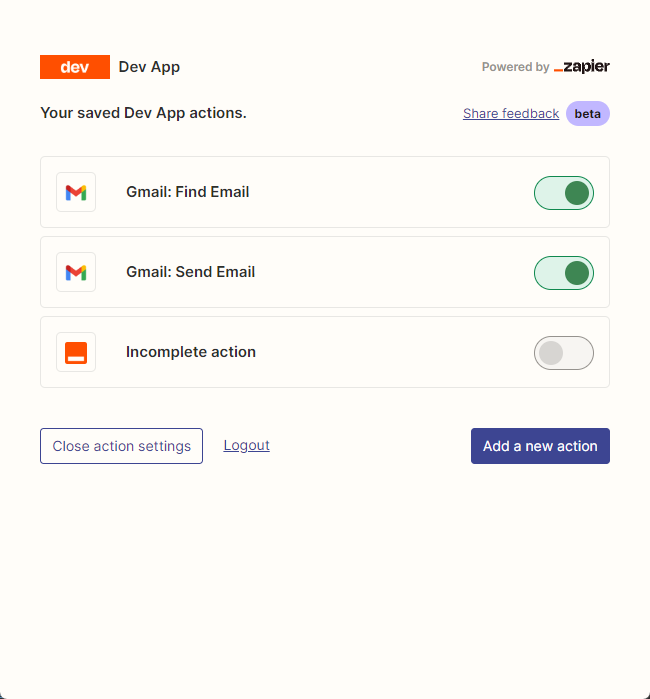
image-20230406233319250
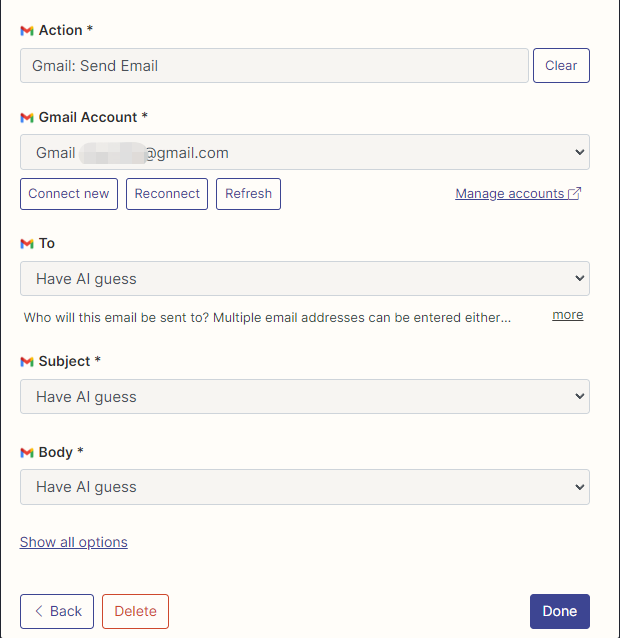
image-20230406234827815
配置好之后,开始写代码
Zapier 发邮件使用示例
import os
os.environ["ZAPIER_NLA_API_KEY"] = ''
from langchain.llms import OpenAI
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits import ZapierToolkit
from langchain.utilities.zapier import ZapierNLAWrapper
llm = OpenAI(temperature=.3)
zapier = ZapierNLAWrapper()
toolkit = ZapierToolkit.from_zapier_nla_wrapper(zapier)
agent = initialize_agent(toolkit.get_tools(), llm, agent="zero-shot-react-description", verbose=True)
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit.get_tools():
print (tool.name)
print (tool.description)
print ("\n\n")
agent.run('请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"')
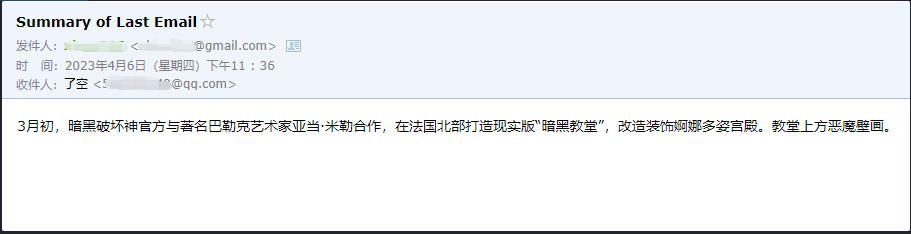
这只是个小例子,因为 zapier 有数以千计的应用,所以我们可以轻松结合 openai api 搭建自己的工作流。