大白话 ChatGPT 及大模型
基础知识介绍
- 指令学习(Instruct Learning):Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。比如“判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差”。Instruction Finetuning 经过多任务精调后,也能够在其他任务上做zero-shot!!
- 提示学习(Prompt Learning):Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Prompting 都是针对一个任务的,比如做个情感分析任务的prompt tuning,精调完的模型只能用于情感分析任务。
- Illustrating Reinforcement Learning from Human Feedback (RLHF):RL 是通过奖励(Reward)机制来指导模型训练,而 RLHF 利用人工反馈训一个Reward Model,并将这个模型作为强化学习的奖励,代替人类去指导大模型进行微调。通过不断地反馈和调整,将模型和人类偏好进行对齐。
微调:采用的是 RL 经典算法 PPO(Proximal Policy Optimization):它是OpenAI提出的一个针对策略梯度算法进行改进的算法,可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。
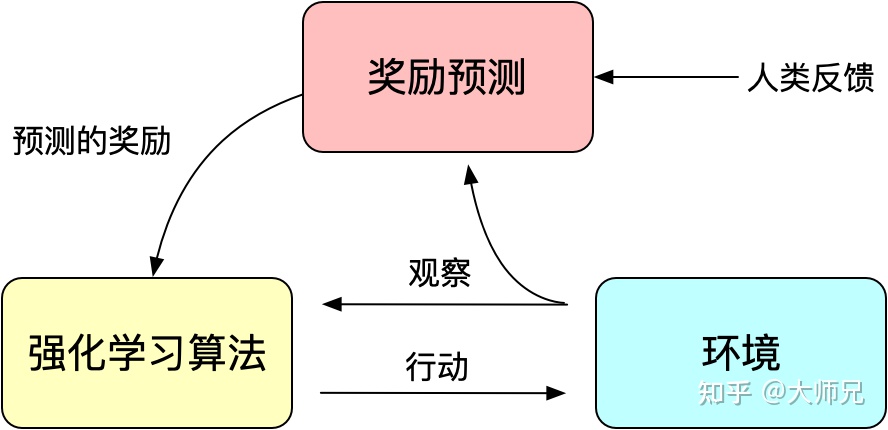
图3:人工反馈的强化学习的基本原理
ChatGPT的本质
ChatGPT(或者更准确地说,它所基于的GPT-3)实际上是在做什么呢?请记住,它的总体目标是基于其从训练中看到的东西(其中包括查看了来自网络等数十亿个页面的文本),“合理地”续写文本。因此,在任何给定的时刻,它都有一定量的文本,并且其目标是为下一个token pick一个适当的选择。

原理总结:
- ChatGPT的实质功能是单字接龙
- 长文由单字接龙的自回归所生成
- 通过提前训练才能让它生成人们想要的问答
- 训练方式是让它按照问答范例来做单字接龙
- 这样训练是为了让它学会「能举一反三的规律」
- 缺点是可能混淆记忆,无法直接查看和更新所学,且高度依赖学习材料。
ChatGPT的三个训练过程

ChatGPT 这个模型建立在 GPT3.5 版本之上,使用基于人工反馈的强化学习 RLHF 进行对齐。ChatGPT的训练过程分为如下几步:
- 用监督数据基于GPT3.5训练一个对话模型SFT,训练数据是标注人员手把手写出来的
- 人工标注对模型生成的多个结果排序,训练一个给对话回复打分的模型(RM)
- 由RM提供reward,利用强化学习的手段(PPO)来训练之前微调过的SFT。
阶段2与阶段3其实是递交进行的。

数据集采集
如上图所示,InstructGPT/ChatGPT的训练分成3步,每一步需要的数据也有些许差异,下面我们分别介绍它们。
① SFT数据集
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
- 简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;
- Few-shot任务:labeler给出一个指示,以及该指示的多个查询-相应对;
- 用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示。
② RM数据集
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。
具体而言,随机抽样一批用户提交的prompt(大部分和第一阶段的相同),使用第一阶段Fine-tune好的冷启动模型,针对每个 prompt 生成K个不同的回答($4≤K≤9$),于是模型产生出了
③ PPO数据集
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
ChatGPT训练: 一阶段
第一阶段:冷启动阶段的监督策略模型 SFT
The “pre-training on a general task + fine-tuning on a specific task” strategy is called transfer learning.
Most state-of-the-art large language models also go through an additional instruction fine-tuning step after being pre-trained. In this step, the model is shown thousands of prompt + completion pairs that were human labeled. Why? While language modeling on Wikipedia pages makes the model good at continuing sentences, but it doesn’t make it particularly good at following instructions, or having a conversation, or summarizing a document (all the things we would like a GPT to do). Fine-tuning them on human labelled instruction + completion pairs is a way to teach the model how it can be more useful, and make them easier to interact with.
尽管 GPT 3.5本身很强,但是它很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令中蕴含的意图,首先会从测试用户提交的 prompt (就是指令或问题)中随机抽取一批,交由专业的标注人员,给出高质量答案,然后用这些人工标注好的

经过这个过程,我们可以认为GPT 3.5初步具备了理解人类prompt中所包含意图,并根据这个意图给出相对高质量回答的能力,但不一定符合人类偏好,并且通常会出现不一致问题。为解决该问题,ChatGPT 的做法是让人工标注者对 SFT 模型的不同输出进行排序,构建一个排序数据集,训练奖励模型 RM,并让训好的 RM 来对 SFT 进行打分,通过RLHF来调整 SFT。
ChatGPT训练: 二阶段
第二阶段:训练回报模型 RM(Reward Model)
这一步的目标是从数据中学习人类的偏好,目的是为 SFT 输出进行打分。它的工作过程为:
- 给定 prompt,SFT 为每个 prompt 生成多个输出(4~9 个)
- 标注者对这些输出进行排序,得到一个新的RM排序数据集;
- 基于此数据集,训练Reward Model。简单做法是,利用大模型做一个回归任务,即在模型的输出层[CLS]位置添加一个MLP,最后得到的数值即为Reward Model给出的分数。

**回归任务该如何训练呢?
如下图所示,在训练Reward Model的时候采用 pair-wise learning to rank,即针对同一个上文,利用一阶段训好的 SFT 输出$K=4$个回复结果,这4个回复之间两两组合可以形成$C_4^2=6$个数据对 pair,优化目标为:每对之中 与上文关系大的分数 高于与上文关系小的。

Reward Model 的损失函数为 pairwise loss:
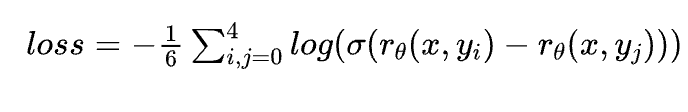
其中$r_θ(x,y)$是奖励值,$y_i$是排名相对靠前的结果,$y_j$是排名相对靠后的结果。这个损失函数的目标是最大化好的回复结果和不好的回复结果之间的差值。
归纳下:在这个阶段里,首先由冷启动后的监督策略模型 SFT 为每个prompt产生K个结果,人工根据结果质量由高到低排序,以此作为训练数据,通过pair-wise learning to rank模式来训练回报模型。对于学好的RM模型来说,输入
chatGPT训练: 三阶段
第三阶段:采用 PPO 强化学习,来增强PLM的能力。
本阶段无需人工标注数据,而是利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数,将此微调任务表述为 RL 问题。
在这一步中,首先随机抽取一批新的 prompt,PPO 模型由SFT模型初始化,价值函数由 RM 模型初始化。期望对 prompt 做出响应。对于给定的 promot和响应,它会产生相应的回报(由 RM模型决定),SFT 模型会对每个 token 添加KL惩罚因子,以尽量避免 RM 模型的过度优化。

First, the policy is a language model that takes in a prompt and returns a sequence of text (or just probability distributions over text). The action space of this policy is all the tokens corresponding to the vocabulary of the language model (often on the order of 50k tokens) and the observation space is the distribution of possible input token sequences. The reward function is a combination of the preference model and a constraint on policy shift.
首先,Policy Model 就是语言模型(即一阶段冷启动后的监督策略模型 SFT),它接收一个提示并返回一个文本序列(或者只是文本的概率分布)。该策略的动作空间是所有对应于语言模型词汇表的 tokens(通常在50k个tokens左右),观察空间是可能的输入token序列的分布。奖励函数是偏好模型(上一阶段训练好的RM模型)和策略转移约束的组合。
The reward function is where the system combines all of the models we have discussed into one RLHF process. Given a prompt, $x$, from the dataset, two texts, $y1, y2$, are generated – one from the initial language model and one from the current iteration of the fine-tuned policy. The text from the current policy is passed to the preference model, which returns a scalar notion of “preferability”, $r_\theta$ . This text is compared to the text from the initial model to compute a penalty on the difference between them. In multiple papers from OpenAI, Anthropic, and DeepMind, this penalty has been designed as a scaled version of the Kullback–Leibler (KL) divergence between these sequences of distributions over tokens, $r_\text{KL}$. The KL divergence term penalizes the RL policy from moving substantially away from the initial pretrained model with each training batch, which can be useful to make sure the model outputs reasonably coherent text snippets. Without this penalty the optimization can start to generate text that is gibberish but fools the reward model to give a high reward. In practice, the KL divergence is approximated via sampling from both distributions (explained by John Schulman here). The final reward sent to the RL update rule is $r = r_\theta - \lambda r_\text{KL}$
奖励函数是系统将上述讨论过的所有模型合并为一个RLHF过程的地方。给定数据集中的提示$x$,生成两个文本$y1$和$y2$,一个来自固定参数不微调的初始语言模型 (initial SFT),另一个来自参数可调的策略模型 (fine-tuned policy SFT)。①当前策略模型的输出文本会输入给偏好模型,得到一个标量的回报“preferability”$r_\theta$。②将这个文本与初始模型的文本进行比较,计算它们之间差异的惩罚。在OpenAI、Anthropic和DeepMind的多篇论文中,这个惩罚被设计为这些tokens分布序列之间的Kullback-Leibler(KL)散度的缩放版本$r_\text{KL}$。在每个 batch,KL散度项会惩罚RL策略,当其向远离初始预训练模型移动,这对于确保模型输出合理的连贯文本片段非常有用。如果没有这个惩罚,优化可能会开始生成无意义的文本,但欺骗奖励模型给出高奖励。在实践中,KL散度是通过从两个分布中进行采样来近似的,至此RL更新规则的最终奖励是$r=r_\theta-\lambda r_\text{KL}$
Some RLHF systems have added additional terms to the reward function. For example, OpenAI experimented successfully on InstructGPT by mixing in additional pre-training gradients (from the human annotation set) into the update rule for PPO. It is likely as RLHF is further investigated, the formulation of this reward function will continue to evolve.
一些RLHF系统在奖励函数中添加了一些额外的项。例如,OpenAI在InstructGPT上成功地进行了实验,将额外的预训练梯度混合到PPO的更新规则中。随着对RLHF系统的进一步研究,这个奖励函数的构建很可能会不断演变。
补充:只用PPO模型进行训练的话,会导致模型在通用NLP任务上性能的大幅下降,OpenAI的解决方案是在训练目标中加入了通用的语言模型目标 $γE_x∼D_{pretrain} [log(π_ϕ^{RL}(x))]$,这个变量在论文中被叫做PPO-ptx。
Finally, the update rule is the parameter update from PPO that maximizes the reward metrics in the current batch of data (PPO is on-policy, which means the parameters are only updated with the current batch of prompt-generation pairs). PPO is a trust region optimization algorithm that uses constraints on the gradient to ensure the update step does not destabilize the learning process. DeepMind used a similar reward setup for Gopher but used synchronous advantage actor-critic (A2C) to optimize the gradients, which is notably different but has not been reproduced externally.
最后,更新规则是从当前数据批次中最大化奖励值的PPO参数更新(PPO是在线策略,这意味着参数只能通过当前的’提示-生成’对进行更新)。PPO是一种信任区域优化算法,它使用梯度约束来确保更新步骤不会破坏学习过程。DeepMind在Gopher中使用了类似的奖励设置,但使用同步 advantage actor-critic (A2C) 来优化梯度,这明显不同,但尚未在外部得到复制。

Optionally, RLHF can continue from this point by iteratively updating the reward model and the policy together. As the RL policy updates, users can continue ranking these outputs versus the model’s earlier versions.
如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
PPO 算法的详细介绍请移步 PPO:Proximal Policy Optimization
ps:为什么是RLHF?
这里我们举一个具体的场景,当我们想要训练一个能够对话的机器人时,
- 强化学习(RL)的reward 需要人来衡量机器人每句对话的好坏(reward),但这显然非常折磨人。
- 模仿学习(IL)不需要人类对机器人的对话做评价,而是机器人反过来模仿人类的对话方式。具体来说,可以从网上或者其它渠道收集大量历史对话数据来训练一个奖赏模型(RM),但是带来了如何收集高质量数据训练RM的问题(如医疗对话等场景)
- 而 RLHF 并不提供直接的监督信号。但通过学习简单的排序,RM可以学到人类的偏好。那怎么去理解这里的“偏好”呢?打个比方,有一家冰箱工厂生产了好几种类型的冰箱,虽然这些客户中没有一个懂得如何造冰箱的(或者说他们不需要懂),但他们可以通过消费行为,让厂商明白消费者对冰箱类型的“偏好”,从而引导冰箱厂商生产销量更好的冰箱。
参考
- 张俊林:ChatGPT会成为下一代搜索引擎吗
- 全网唯一,不忽悠的ChatGPT
- 视频:《【渐构】万字科普GPT4为何会颠覆现有工作流;为何你要关注微软Copilot、文心一言等大模型》,适合零基础小白 www.bilibili.com
- 视频:《手把手从头实现GPT by Andrej Karpathy》,适合有基本编程概念的初学者 www.bilibili.com
- 课程:《李宏毅2023春机器学习课程》,适合有简单线代和编程基础、想要系统学习Machine Learning的用户 www.bilibili.com