LLAMA Fine-tune

LLaMA 概要与实践
LLaMA(Large Language Model Meta AI) 是由 Meta AI 发布了一款全新的大型语言模型,共有7B、13B、33B、65B 四种版本,其模型参数如下表所示:
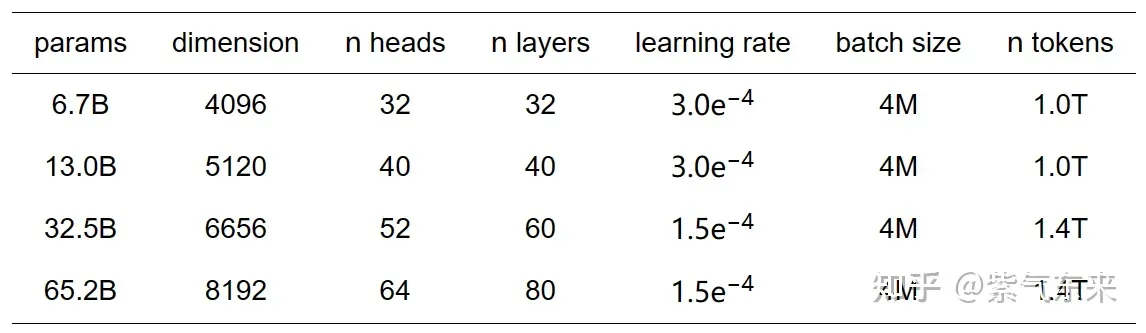
LLaMA模型参数表
与原始的 transformer Decoder 相比,LLaMA主要有以下改进:
- 层归一化(Pre-normalization)[GPT3]
为了提高训练的稳定性,LLaMA 使用了Pre-norm,即对每个transformer子层的输入进行归一化,而不是对输出进行归一化。同时使用RMSNorm归一化函数。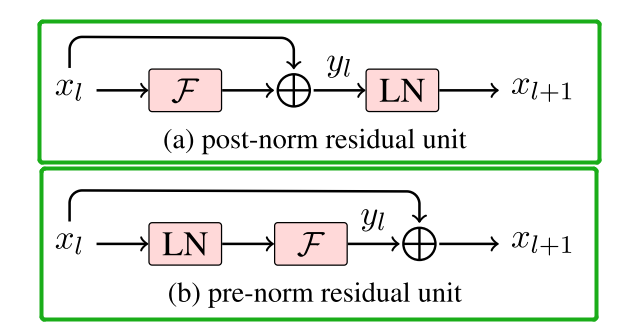
- SwiGLU激活函数[PaLM]
LLaMA用SwiGLU激活函数取代ReLU非线性,以提高性能。SwiGLU激活函数的实现如下: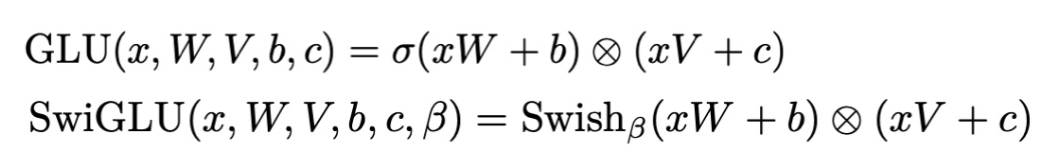
- Rotary Positional Embedding (RoPE) [RoFormer]
LLaMA删除了绝对位置嵌入,取而代之的是在网络的每一层添加旋转位置嵌入(RoPE),RoPE的实现参见 https://nn.labml.ai/transformers/rope/index.html
Alpaca 使用小成本训练大模型
Standford Alpaca 地址:https://github.com/tatsu-lab/stanford_alpaca
如下图所示,Stanford的研究者将 175 个人工设计的指令任务作为种子,使用 text-davinci-003,以 self-instruct 方式随机生成 52K 指令,以此来微调 LLaMA 7B,这个数据集本身还不是很干净导致Alpaca-lora的老哥们后来还给它清洗了一遍。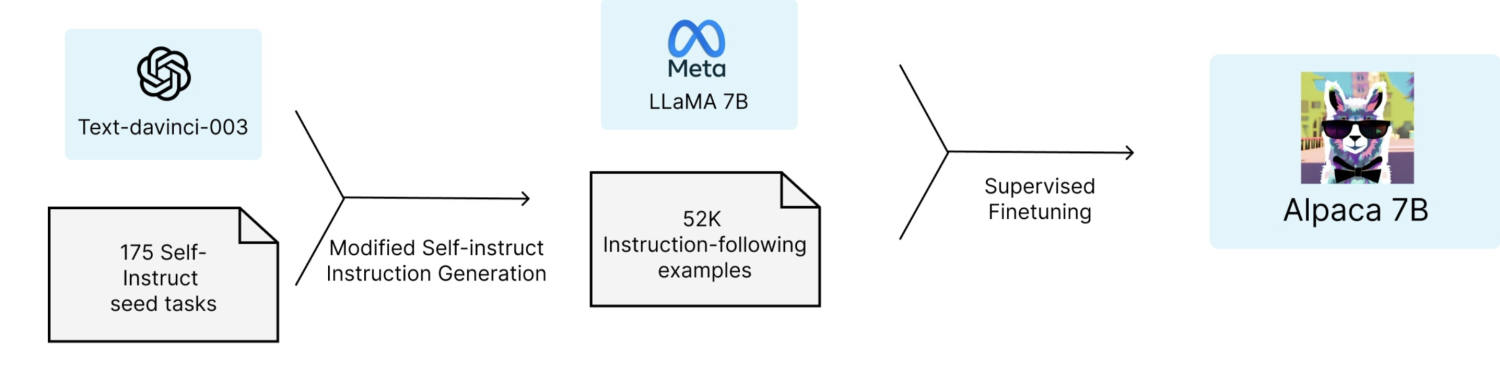
Alpaca精悍于:
- 直接嫖了Meta开源模型Llama-7B,在 8 块 80GB A100 显卡,训练 3 小时;
- 直接嫖了ChatGPT生成可靠训练数据,无需人工标注;借鉴self-instruct的方式,利用175 个 prompts 种子和 chatgpt 来批量的生成 52K 指令数据集(问答对),大幅降低了训练成本;
- 600$ 不到的成本,实验效果与GPT-3.5相当;
- Web Demo: https://crfm.stanford.edu/alpaca/
Alpaca 的优化
Alpaca 通过全参数的指令微调,获得了与GPT-3.5相当的效果。虽然指令微调相比于预训练更加高效(只需要处理微调数据集),但是全参数的指令微调依然需要消耗较多的算力。目前有多种高效参数微调PEFT方案,可以在实现和全参数微调相同性能的情况下,大幅降低微调成本。
alpace-lora 是在alpaca的基础上把训练方式改成用lora训练,仅需要一块消费级的GPU,经过数小时 7B 模型的 fine-turning,就可以达到和alpaca差不多的效果。
- Alpaca-Lora 地址:https://github.com/tloen/alpaca-lora
- 参数高效微调 PEFT 技术简介:https://www.yuque.com/ningshixian/pz10h0/hupu29k9t412t8u2?singleDoc#
如何让模型自举生成数据
参考链接
1.设计chatgpt的提问prompt元模版
2.收集提问的问题,对问题做些总结归类,抽出问题元模版
3.根据元模版衍生出种子问题
4.prompt元模版和种子问题拼接生成prompt,让chatgpt批量生产问题
5.把相似度问题合并
6.把chatgpt自己生产的问题作为prompt,让chatgpt回答
7.把6步生成的数据集后处理作为自己模型alignment的语料
微调一个自己的 Alpaca
基于龙湖对话知识的Llama微调模型
BiLLa:更擅长推理的LLaMA大模型,支持中文!
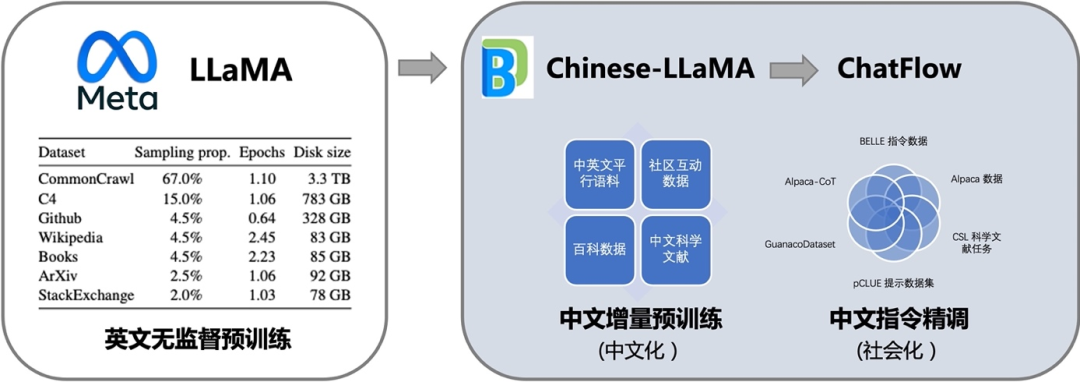
我们希望基于LLaMA+instruction数据构建一个中文的羊驼模型,基本思路就是用PEFT的lora接口+transformer的trainer+instruction的数据配置。
需要进行如下3个阶段的训练:
- 二次Pre-training阶段:扩充中文词表,使用中文预训练语料Wudao、英文预训练语料PILE、翻译语料WMT的中英数据进行二次预训练(可跳过,或直接使用 BiLLa-7B-LLM 或 Chinese-LLaMA-7B)
- 中文指令精调阶段:利用中文指令数据(如 Alpaca GPT4、COIG、BELLE、GuanacoDataset、pCLUE 等,尽可能保证任务的多样性),然后通过语言建模任务,来微调 LLAMA 7B,提升模型对任务求解逻辑的理解
- 对话微调 (Conversation Tuning):像 Alpaca 一样,收集 input/output 生成 prompt 用于训练,或者将上述数据转化为对话格式后训练,让模型完成特定任务。
第一步:准备数据集
找数据集哪里找?
推荐Alpaca-COT,整理了一个intruction-finetuning的数据集集合,包含了中文、英文和CoT的instruction数据
1、通用中文指令微调:语言填充,收集文本用于训练,让模型补全 prompt。可以采用下面几份高质量的公开语料
| 数据集 | 内容 |
|---|---|
| Stanford Alpaca (Chinese) | Alpaca 数据集中文翻译(ChatGPT 辅助翻译) |
| BELLE √ | BELLE 项目的中文数据集(ChatGPT 生成) |
| GuanacoDataset √ | Guannaco 模型的对话数据集 |
| WebQA(zh) | 中文网络问答 |
| pCLUE | 基于提示的大规模预训练数据集,用于多任务学习和零样本学习 |
Chinese-Vicuna 提供了BELLE 和 GuanacoDataset 的整合数据,可以通过HuggingFace下载 https://huggingface.co/datasets/Chinese-Vicuna/guanaco_belle_merge_v1.0
通用指令微调效果
指令微调可以让大模型有质的提升,主要体现在两个方面:
- 性能改进:最近的研究发现经过指令微调的较小模型甚至可以比未经微调的较大模型表现更好。除了模型规模外,指令微调在不同的模型架构、预训练目标和模型适应方法上都展现出持续的改进效果。在实践中,指令微调为提升现有语言模型(包括小型预训练语言模型)的能力提供了一种通用的方法 。此外,与预训练相比,指令微调成本较低,因为大语言模型所需的指令数据数量明显较少于预训练数据。
- 任务泛化性:指令微调鼓励模型理解用于任务完成的自然语言指令。它赋予大语言模型遵循人类指令执行特定任务的能力(通常被视为一种涌现能力),即使在未见过的任务上也能够执行 。大量研究已经证实了指令微调在已见和未见任务上实现卓越的性能表现。此外,指令微调还被证明对缓解大语言模型的一些弱点(如生成重复内容或在不完成特定任务的情况下补充输入)具有帮助,从而使大语言模型具有更强的解决现实世界任务的能力。此外,通过使用指令微调训练的大语言模型可以在不同语言之间泛化到相关任务。
2、对话微调 (Conversation Tuning):像 Alpaca 一样,收集 input/output 生成 prompt 用于训练,让模型完成特定任务。对话微调是一种特殊的指令微调。其目的是让大语言模型在「补全」能力的基础上,解锁「对话」能力。
| 数据集 | 内容 |
|---|---|
| fnlp/moss-002-sft-data | MOSS-002所使用的多轮对话数据,包含由text-davinci-003生成的约57万条英文对话和59万条中文对话。 |
| trans_chinese_alpaca_data.json | Luotuo 作者翻译的 Alpaca 数据集 |
具体的对话格式应该和模型在预训练以及微调时保持一致. 示例如下:1
2
3
4
5
6
7
8
9
10[{
"instruction":
"input":
"output":
}]
[
"{instruction} input
=> output"
]
第二步:指令微调
1、alpaca-lora 训练
GPT fine-tune实战: 训练我自己的 ChatGPT - 知乎
使用Alpaca-Lora基于LLaMA(7B)二十分钟完成微调
柿子挑软的捏,我们从简单的目标开始:让模型讲中文。
为了达成这个目标,我使用的数据集是 Luotuo 作者翻译的 Alpaca 数据集,训练代码主要来自 Alpaca-LoRA。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73# 下载 alpaca-lora 项目
git clone https://github.com/tloen/alpaca-lora.git
# 下载训练数据
# Luotuo 作者翻译的 Alpaca 数据集
wget https://raw.githubusercontent.com/LC1332/Chinese-alpaca-lora/main/data/trans_chinese_alpaca_data.json
# 手动下载 BELLE 和 GuanacoDataset 的整合数据
yum install git-lfs
git lfs install
# 从Hugging Face下载转换好的 LLaMA-7B 模型权重
git lfs clone https://huggingface.co/decapoda-research/llama-7b-hf
git lfs clone https://huggingface.co/yahma/llama-7b-hf
# lora权重下载
# 官方提供
git lfs clone https://huggingface.co/tloen/alpaca-lora-7b
# Chinese-Vicuna 在上面混合数据上训练的lora模型
git lfs clone https://huggingface.co/Facico/Chinese-Vicuna-lora-7b-3epoch-belle-and-guanaco
# luotuo提供
git lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1
# 激活 56 虚拟环境
source activate gptenv
cd alpaca-lora
# train
# V100 建议不开启 int8 训练 + 提高 low_rank
python finetune.py \
--base_model '../llama-7b-hf' \
--data_path '../trans_chinese_alpaca_data.json' \
--output_dir './lora-alpaca-zh' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 3e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]'
# 断点重训/增量训练
# 需要设置resume_from_checkpoint
# V100 建议不开启 int8 训练 + 提高 low_rank
CUDA_VISIBLE_DEVICES=2 torchrun --nproc_per_node=1 finetune.py --base_model '../llama-7b-hf' --data_path '../lf_instruct_15k.json' --output_dir './lora-alpaca-zh' --num_epochs 10 --lora_r 8 --resume_from_checkpoint '../lora-weights/Chinese-Vicuna-lora-7b-3epoch-belle-and-guanaco'
# multi-GPU train
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,2 torchrun \
--nproc_per_node=2 \
--master_port=29005 \
finetune.py \
--base_model '../llama-7b-hf' \
--data_path '../trans_chinese_alpaca_data.json' \
--output_dir './lora-alpaca-zh' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3
# inference
CUDA_VISIBLE_DEVICES=2 python generate.py --base_model '../llama-7b-hf' --lora_weights './lora-alpaca-zh' --share_gradio true
# --load_8bit False\
# 将 LoRA 权重合并回基础模型, 通过 llamap.cpp 等项目达到更好的推理性能
# 重新导出为 HuggingFace 格式和 PyTorch state_dicts
export BASE_MODEL='../llama-7b-hf'
export LORA_WEIGHTS='../luotuo-lora-7b-0.1'
# export to Hugging Face format
python export_hf_checkpoint.py
# export to PyTorch state_dicts
python export_state_dict_checkpoint.py
验证效果 & 输出向量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained('./hf_ckpt', torch_dtype="auto", device_map="auto")
tokenizer = LlamaTokenizer.from_pretrained('./hf_ckpt')
input_text = "What is the meaning of life?"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
output_ids = model.generate(input_ids)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)
# 获取 llama 编码的 sentence embedding
output = model.model.forward(input_ids)
emb = torch.mean(output.last_hidden_state, dim=1)
print(emb.shape) # (1, 4096)
注意
1、如果遇到“fine-tune过程中loss会忽大忽小”或“生成结果乱码”这两个问题时,大概率是 「 使用V100+启用 8bit 模式训练」导致的,解决方法请参考下面的 Issue
—> 为什么fine-tune过程中loss会忽大忽小呢? #39
—> 采用V100的显卡做lora微调时loss异常 #1221
2
3
4
5
6
7
8
9
10# 112 行
model = LlamaForCausalLM.from_pretrained(
base_model,
load_in_8bit=False, # V100建议不要开启
torch_dtype=torch.float16,
device_map=device_map,
).half()
# 174行 注释掉
# model = prepare_model_for_int8_training(model)
2、如果效果不好(复读机、胡说八道),可能有以下问题:
- 生成的时候没有使用beam search,Repetition Penalty,temperature等参数
- 数据量偏少,且训练的 epoch 不够充分导致的;
- lora的low rank偏小,可以调大些 https://github.com/Facico/Chinese-Vicuna/issues/140
- LLAMA 可能未学习到结束标记 eos_token_id,需要检查是否都正常。参考#279
- #325 finetune alpaca-lora with custom dataset got poor results 中的解决方案是用最后一个checkpint目录中的 pytorch_model.bin 文件替换保存的模型文件 adapter_model.bin,最终的推理过程似乎就 OK 了,可行!
- #286 model.save_pretrained() produced a corrupted adapter_model.bin (only 443 B) with alpaca-lora 发现由于alpaca-lora下面的这部分代码,导致调用 save_pretrained() 方法时返回 None,尝试了删除/注释掉这部分代码,最后可以解决模型保存仅有 443B 大小的问题!
1
2
3
4
5
6
7
8
9# old_state_dict = model.state_dict
# model.state_dict = (
# lambda self, *_, **__: get_peft_model_state_dict(
# self, old_state_dict()
# )
# ).__get__(model, type(model))
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
model.save_pretrained(output_dir)
结语
从上面可以看到,在一台8卡的V100服务器上面,基于Alpaca-Lora针对指令数据进行 10 个 epochs 的 LLAMA 7B 训练,大概 xx 个小时左右即可完成参数高效微调,相对于斯坦福羊驼训练速度显著提升。
2、Lit-LLaMA 实战×
用 Fabric 加速 LLaMA:训练和微调 LLaMA 的综合指南
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
Lit-LLaMA 是 LLAMA 模型的复现 ,代码可读性高,支持量化、LoRA微调、预训练。Lit-LLaMA 的主要亮点是它是在 Apache 2.0 许可下发布的,可以实现商业用途。它具有用于使用LoRA进行优化训练和微调的脚本,可以在具有 8 GB 内存的 GPU 上运行 Lit-LLaMA 🤯。
微调数据集是此处描述的 Alpaca 52k 指令数据集,具有以下结构:1
2
3
4
5{
"instruction":
"input":
"output":
}
具体操作方法如下:
- 下载预训练权重 [ download_weights.md ]
- 使用 LoRA 进行微调 [ finetune_lora.md ]
- 使用 Adapter 进行微调 [ finetune_adapter.md ](可选,用于比较研究)
- 运行预测脚本 [ inference.md ]
1 | |
3、ChatGLM-6B 实战
https://github.com/mymusise/ChatGLM-Tuning
基于 P-tuning v2 的高效参数微调。具体使用方法详见 ptuning/README.md
1 | |
4、BELLE 实战
1 | |
实验过程记录
超参设置和实验过程可以参考wandb的链接:
https://wandb.ai/thinksoso/llama_med/runs/a5wgcnzt/overview?workspace=user-thinksoso
模型效果
LLAMA 对齐
ColossalChat 是第一个基于LLaMA预训练模型开源完整RLHF pipline实现,包括有监督数据收集、有监督微调、奖励模型训练和强化学习微调。只需要不到100亿个参数,就可以在大型语言模型的基础上通过RLHF微调达到中英文双语水平,达到与ChatGPT和GPT-3.5相当的效果,并可以进行Demo测试。
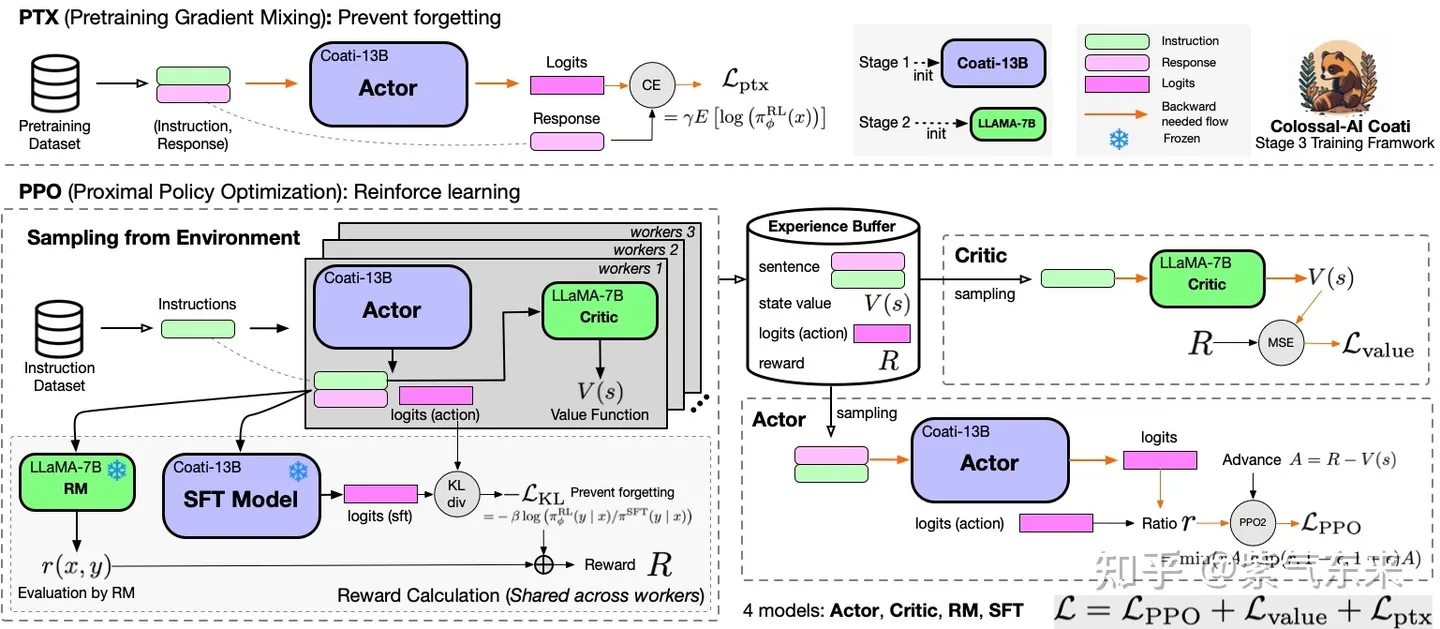
具体实操可参考 https://www.yuque.com/ningshixian/pz10h0/vikg2a9mx2sxso7v?singleDoc# 《基于ColossalAI的ChatGPT最小复现》、以及https://www.yuque.com/ningshixian/pz10h0/dw0fehfpzpv3eweu?singleDoc# 《StackLLaMA:用 RLHF 训练 LLaMA 的手把手教程》
参考
NLP(九):LLaMA, Alpaca, ColossalChat 系列模型研究
大语言模型(LLM)微调技术笔记
BiLLa:更擅长推理的LLaMA大模型,支持中文!
- Colossalai训练框架,8卡V100,batch size 160,4000+ gpu hours
Chinese-Vicuna: A Chinese Instruction-following LLaMA-based Model —— 一个中文低资源的llama+lora方案
《AI 研发提效研究:自己动手训练 LoRA》